이번 시간에는 데이터 구조 전처리 중 마지막 파트인 '전개'입니다.
만약 앞의 내용이 기억이 안 난다면 복습하고 와서 보시면 더 이해가 잘 될 것입니다.
[데이터 전처리#1] 데이터 전처리 개요
최근 인터넷과 전자 기기들의 발달로 매일 엄청난 양의 데이터가 생성되고 있습니다. 그리고 자연스럽게 관련 기술인 인공지능, 머신러닝, 딥러닝 등이 주목받게 되었습니다. 실제로 많은 조직
just-data.tistory.com
전개
데이터 집계 결과를 표 형식으로 변환하는 전개는 전처리에서 빼놓을 수 없습니다.
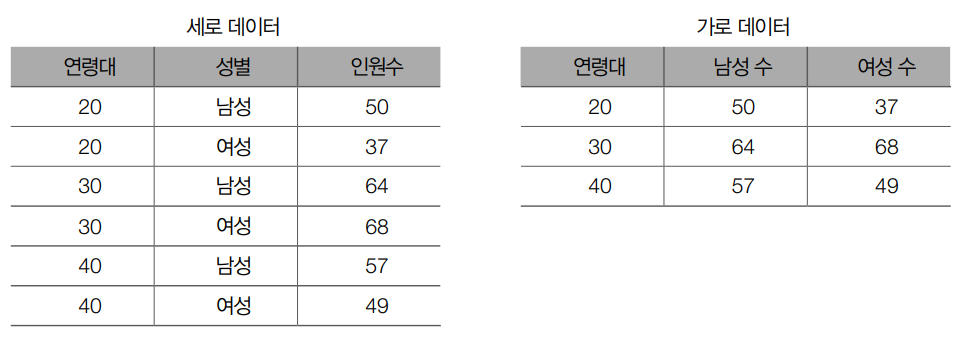
가로 데이터 vs 세로 데이터
가로 데이터는 데이터를 표 형식으로 나타냅니다.
다시 말해, 행은 적고 열은 많은 특징을 가지고 있습니다.
반면 세로 데이터는 데이터가 레코드 형식일 때를 의미합니다.
새로 데이터는 같은 값이 반복된다는 특징이 있습니다.
따라서 행은 많고 열은 적습니다.
같은 말로 wide data, long data라고 부르기도 합니다.
가로 데이터로 변환

# 예약 테이블에서 고객 수 및 투숙객 수에 따른 예약 건수를 세서 행을 고객 ID, 열을 투숙객 수, 값을 예약 건수인 표로 변환
pd.pivot_table(df, index = "customer_id", # 집합을 표시할 킷값
columns = "people_num", # 매개변수에 데이터 용소의 종류를 나타낼 킷값
values = "reserve_id", # 지정된 열 값
aggfunc = lambda x: len(x),
fill_value = 0)
오늘은 짧게 가로 데이터와 새로 데이터에 대해 알아보았습니다.
데이터 분석의 형태에 따라 필요한 데이터 형태는 다양할 것입니다.
이를 자유롭게 다룰 수 있으면 데이터 전처리 과정에서 분명 이점이 있을 것입니다.
지금까지 데이터 구조 전처리에 대해 살펴보았습니다.
다음 포스팅부터는 데이터 내용 전처리를 다루도록 하겠습니다.
포스팅 내용 중 다른 생각이 있는 분 혹은 수정해야 할 부분이 있으시면 댓글을 통해 그 의견을 나눠보면 너무 좋을 것 같습니다.
※ 본 포스팅의 내용은 데이터 전처리 대전을 참고하였습니다.
'Data preprocessing' 카테고리의 다른 글
| [데이터 전처리#5] 데이터 구조 전처리 - 생성 (1) | 2023.07.10 |
|---|---|
| [데이터 전처리#4] 데이터 구조 전처리 - 결합 (0) | 2023.07.04 |
| [데이터 전처리#3] 데이터 구조 전처리 - 집약 (0) | 2023.07.04 |
| [데이터 전처리#2] 데이터 구조 전처리 - 추출 (0) | 2023.07.02 |
| [데이터 전처리#1] 데이터 전처리 개요 (0) | 2023.06.29 |