산업이 발달하기 시작하면서 대부분의 기술들이 인간의 편의를 줄이기 위해 발전되었습니다. 그중 하나가 머신러닝이라고 할 수 있는데요. 예를 한번 들어봅시다.
우리가 흔히 아는 '스팸 메일'의 같은 경우, 지금은 자동으로 스팸메일을 잘 분류해 주지만 초기에는 아마 다음과 같은 방법으로 분류했을 겁니다.
- 스팸 메일에서 자주 등장하는 단어 파악 Ex. 신용카드, 무료, 펀드 등
- 해당 단어가 등장하는 메일을 프로그램이 발견했을때, 그 메일을 스팸으로 분류
- 충분한 성능이 나올 때까지 1단계와 2단계를 반복

초반에는 위의 방법이 잘 통할수 있지만 시간이 지날수록 등장하는 단어의 규칙, 방법 등이 다양해지면서 수작업으로 규칙을 모두 정의하는 것은 매우 힘들어졌을 겁니다(또한 비용도 많이 들어가죠.).
따라서 스팸과 같은 문제에 빈번하게 나타나는 패턴을 스스로 학습하는 도구(머신러닝)의 필요성이 대두되었습니다.
머신러닝이란?

머신러닝은 여러 정의가 있는데 크게 2가지만 알아보겠습니다.
- 명시적인 프로그래밍 없이 컴퓨터가 학습하는 능력을 갖추게 하는 연구분야(Arthur Samuel, 1959)
- 어떤 작업 T에 대한 컴퓨터 프로그램의 성능을 P로 측정했을 때 경험 E로 인해 성능이 향상됐다면, 이 컴퓨터 프로그램은 작업 T와 성능 측정 P에 대해 경험 E로 학습한 것이다(Tom Mitchell, 1997).
머신러닝은 다음과 같은 분야에 뛰어납니다.
- 많은 수동 조정과 규칙이 필요한 문제
- 전통적인 방식으로는 해결 방법이 없는 복잡한 문제
- 유동적인 환경
- 복잡한 문제와 대량의 데이터에서 통찰 얻기
머신러닝의 종류
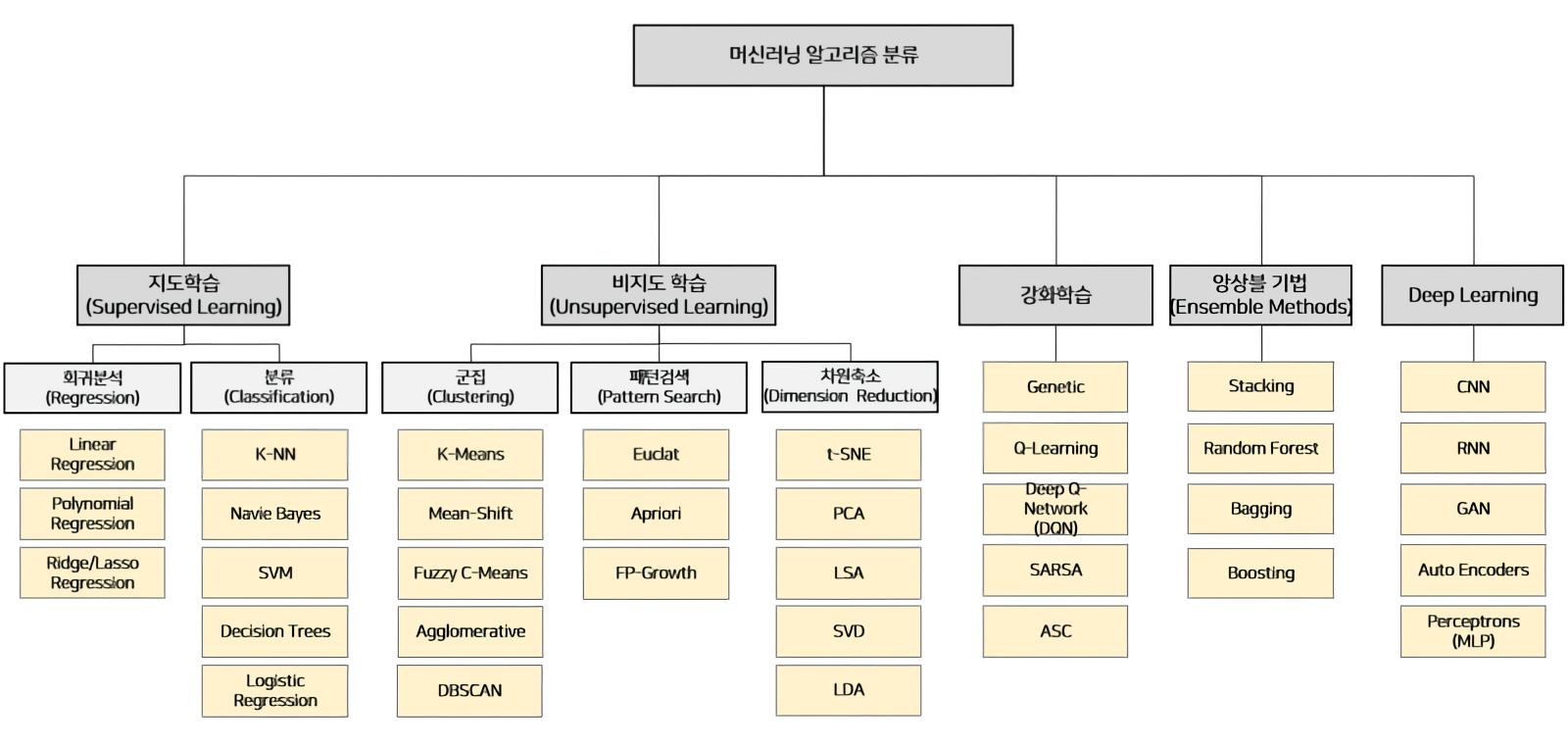
머신러닝의 종류는 굉장히 방대하기 때문에 상황에 맞는 알고리즘을 잘 알고있어야 합니다.
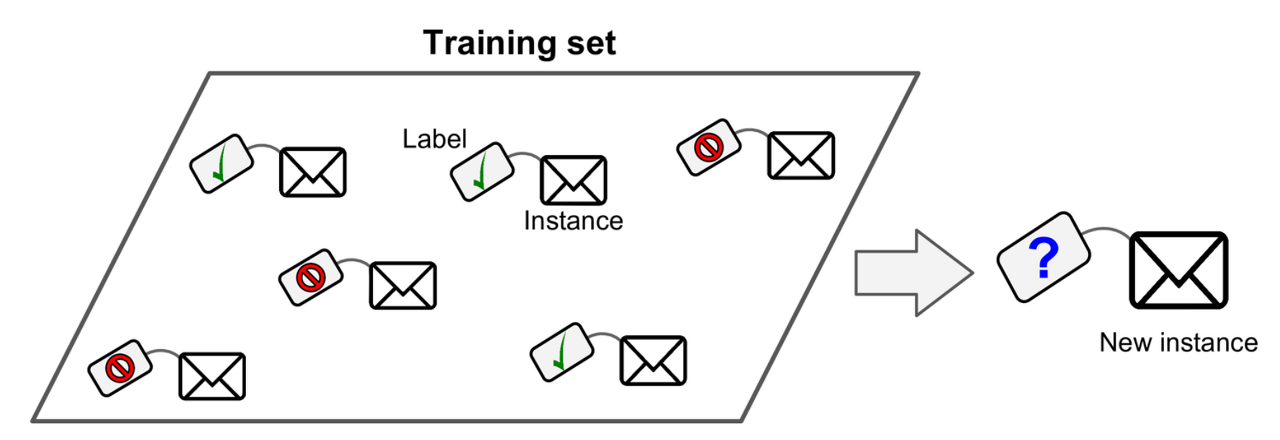
지도 학습
훈련 데이터에 label이라는 원하는 답을 학습하는 것을 의미합니다.
크게 분류와 회귀로 나눌 수 있습니다
※해당 모델이 둘중 하나로만 사용된다는 것이 아닙니다. 주로 사용되는 분야로 나눈것입니다.
1. 분류
2. 회귀
회귀에서도 y라는 특정한 값이 존재하기 때문에 지도학습으로 분류됩니다.

비지도 학습
지도학습과 반대로 label이 존재하지 않습니다. 따라서 특정 알고리즘을 통해 스스로 학습해야 합니다.
즉, 데이터에 대한 정보가 부족할 때 유용하며 데이터를 파악하는데 도움을 받을 수 있습니다.
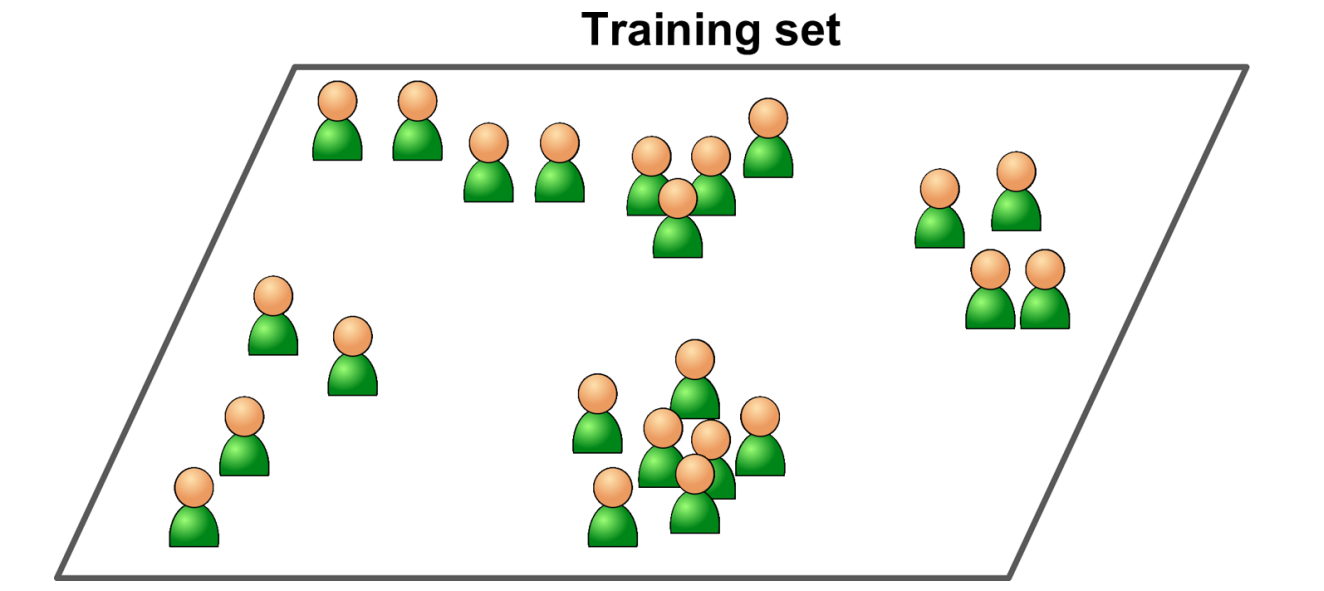
준지도 학습
지도학습과 비지도 학습을 혼합한 방식으로 일부만 레이블이 존재하는 데이터를 학습하는 방법입니다.
Ex. 구글 포토 호스팅: 사진을 인식할 때(비지도 학습), 사진속 인물이 누구인지 입력(지도학습)
강화 학습
알고리즘이 어떤한 행동을 했을때의 결과로 보상 또는 패널티를 부여하여 시간이 지나면서 가장 큰 보상을 받기 위한 방향으로 학습하는 알고리즘을 의미합니다.
Ex. 딥마인드, 알파고
이번 시간에는 머신러닝의 정의와 알고리즘 종류에 대해 간단히 알아보았습니다. 이후부터는 대표적인 알고리즘에 관한 설명과 파이썬으로 구현하는 것을 올려보도록 하겠습니다.
포스팅 내용중 다른 생각이 있는 분 혹은 수정해야할 부분이 있으시면 댓글을 통해 그 의견을 나눠보면 너무 좋을 것 같습니다.
※ 본 포스팅의 내용은 핸즈온 머신러닝를 참고하였습니다.
'Machine Learning' 카테고리의 다른 글
| [머신러닝#4] 지도학습 - 의사결정 나무(Decision Tree) (0) | 2023.07.06 |
|---|---|
| [머신러닝 기본#2] 경사 하강법 (0) | 2023.06.30 |
| [머신러닝 기본#1] 분류 (0) | 2023.06.29 |
| [머신러닝#3] 지도 학습 - 로지스틱 회귀(Logistic Regression) (0) | 2023.06.29 |
| [머신러닝#2] 지도 학습 - KNN (0) | 2023.05.11 |