이번 포스팅을 원래 가장 먼저 다루었어야 했는데 이제야 올리게 되었습니다.
지도 학습은 크게 회귀와 분류로 나눌 수 있습니다.
이때 대부분의 내용은 비슷하지만 학습 결과를 확인하는 과정 등 조금씩 다른 몇몇 부분이 존재합니다.
그래서 이번 포스팅에서는 분류 시스템에 집중적으로 다루어보도록 하겠습니다.
전체적인 과정과 결과를 해석하는 법을 알고 나면 이후 다른 모델을 적용하실 때 더 수월할 것입니다.
데이터 불러오기
아주 유명한 분류 데이터인 MNIST를 사용하도록 하겠습니다.
from sklearn.datasets import fetch_openml
mnist = fetch_openml("mnist_784", version = 1, as_frame = False)
X, y = mnist["data"], mnist["target"]
y = y.astype(np.uint8)X와 y의 shape을 확인해 보면 70,000개의 이미지와 784개의 특징이 존재합니다.
이는 28 * 28로 흑백 이미지라는 것을 알 수 있습니다.
첫 번째 사진을 시각화해보면 다음과 같습니다.
import matplotlib as mpl
import matplotlib.pyplot as plt
some_digit = X[0]
some_digit_image = some_digit.reshape(28, 28)
plt.imshow(some_digit_image, cmap = "binary")
plt.axis("off")
plt.show()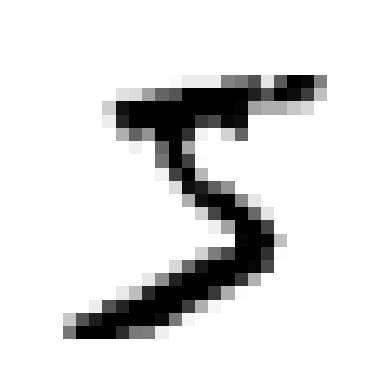
다른 샘플들도 확인해 보시면 사람들의 글씨체가 이렇게 다양하구나라는 것을 알 수 있습니다.

이어서 학습데이터와 테스트 데이터로 나누어 주겠습니다.
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]다중 분류
이진 분류는 다중 분류의 특별 케이스이기 때문에 전체적인 분류 시스템의 과정을 알려드리기 위해 다중 분류를 하도록 하겠습니다.
여기서는 서포트 벡터 머신을 사용했습니다.
※ 이전 포스팅에서 설명드렸지만 이진 분류기로도 다중 분류가 가능합니다.
from sklearn.svm import SVC
svm_clf = SVC()
성능 분석
먼저 모델의 성능을 accuracy 관점에서 확인해 보겠습니다.
k-fold cross validation을 통해 평가하였습니다.
from sklearn.model_selection import cross_val_score
cross_val_score(svm_clf, X_train, y_train, cv = 3, scoring = "accuracy")
평균 97%의 정확도로 매우 정확한 수치가 나왔습니다.
하지만 이 수치만으로 모델의 성능을 모두 확인했다고는 볼 수 없습니다.
정확도의 수치 특성상 불균형 데이터셋에서 편향된 수치가 나올 수 있기 때문입니다.
따라서 정확도 외 여러 수치들을 검토해야 합니다.
대표적으로 정확도를 포함한 정밀도, 재현율입니다.
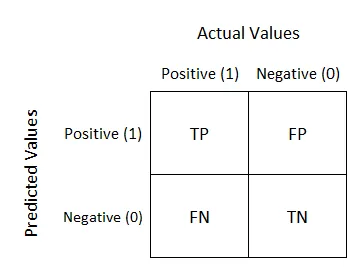
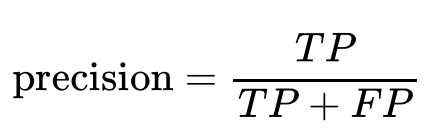

상황을 통해서 이해해 봅시다
예를 들어 코로나 격리 대상자를 분류하는 작업을 하고 있다고 생각해 볼 때,
정밀도(precision)는 격리 대상자(양성)로 분류한 사람들 중 실제 양성일 확률을 의미합니다.
재현율(recall)은 양성인 사람들 중 격리 대상자(양성)로 분류된 확률을 의미합니다.
분자는 모두 TP로 같지만 분모에 따라서 의미가 조금씩 달라지게 됩니다.
※ 정밀도의 경우 격리를 시킨 사람들 중 음성이 있을 수도 있지만, 재현율의 경우 양성임에도 불구하고 격리를 시키지 않은 상황이 나올 수 있습니다.
이러한 뜻의 차이로 인해 정밀도와 재현율은 서로 트레이드 오프의 성질을 가질 수밖에 없습니다.
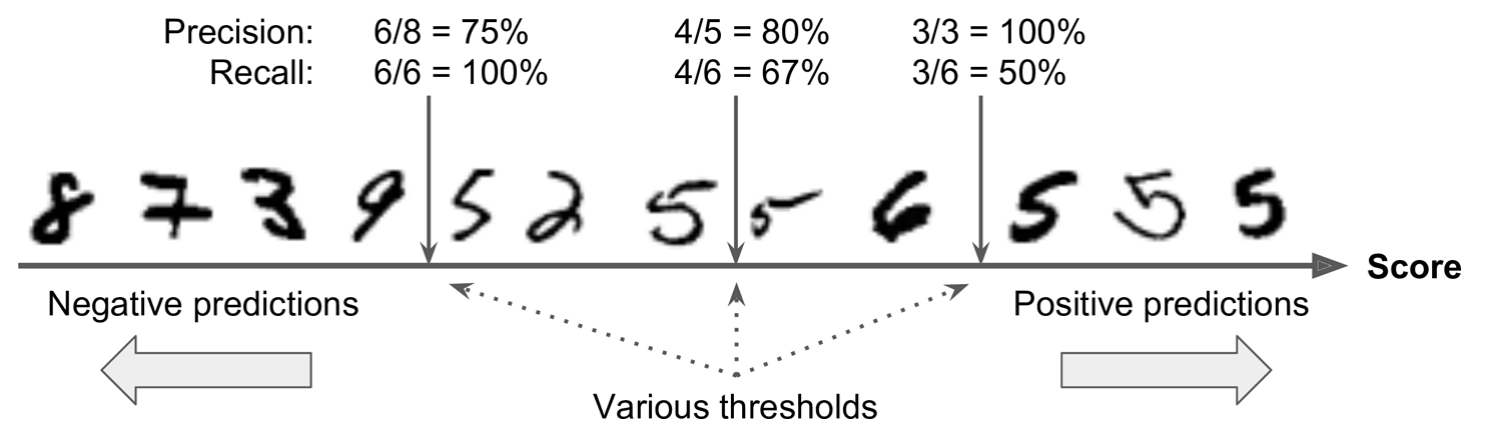
그럼 정밀도와 재현율 중 어떤 수치를 사용해야 할까요?
상황마다 다르지만 대부분의 경우 정밀도와 재현율을 골고루 반영시키고 싶어 합니다.
그래서 $f1-score$를 만들게 됩니다.
이는 아래와 같이 정밀도와 재현율의 조화 평균으로 계산됩니다.

from sklearn.metrics import precision_score, recall_score, f1_score
print(precision_score(y_train, y_train_pred, average="macro"))
print(recall_score(y_train, y_train_pred, average="macro"))
print(f1_score(y_train, y_train_pred, average="macro"))
다중 분류에서는 양성, 음성으로 나눠지지 않기 때문에 macro 방식(모든 레이블에 대한 평균)을 사용해서 각 수치를 계산하였습니다.
※ 이진 분류에서는 average 옵션을 사용하지 않으셔도 됩니다.
대부분의 수치가 잘 나왔습니다.
하지만 모델의 성능이 잘 안 나올 때 어떤 클래스에서 문제가 발생하는지 알고 싶을 수 있습니다.
이럴 때 오차행렬을 조사하는 것이 좋은 방법입니다.
from sklearn.model_selection import cross_val_predict
from sklearn.metrics import confusion_matrix
y_train_pred = cross_val_predict(svm_clf, X_train, y_train, cv = 3)
conf_mx = confusion_matrix(y_train, y_train_pred)
conf_mx
오차 행렬의 행은 실제 클래스를 나타내고 열은 예측한 클래스를 나타냅니다.
여기서 어떤 부분에서 많은 오류가 발생했는지 알 수 있습니다.
좀 더 보기 좋게 음영으로 나타내보겠습니다.
※ 클래스마다 개수가 다르기 때문에 에러 비율로 바꾸어 표현했습니다.
import matplotlib.pyplot as plt
row_sums = conf_mx.sum(axis = 1, keepdims = True)
norm_conf_mx = conf_mx / row_sums
np.fill_diagonal(norm_conf_mx, 0)
plt.matshow(norm_conf_mx, cmap = plt.cm.gray)
plt.show()
이미지를 통해 3, 5, 8에서 많이 혼동되고 있음을 알 수 있습니다.
따라서 지금 성능도 너무 좋지만 더 향상시키기 위해서는 3, 5, 8에 대한 데이터를 추가하거나 전처리를 해줄 필요가 있다는 insight를 얻을 수 있습니다.
ROC 곡선
마지막으로 이진 분류에서 널리 사용되는 ROC 곡선이 있습니다.
ROC 곡선은 거짓 양성 비율(FPR)에 대한 진짜 양성 비율(TPR)의 곡선입니다.
※ 정밀도/재현율 곡선과 다릅니다.
TPR(True Positive Rate)은 recall과 같은 개념입니다.
FPR(False Positive Rate)은 $1-TNR$로 여기서 TNR 개념이 등장합니다.
※ $1-TNR$로 유도되는 과정이 있지만 생략하겠습니다.
TNR(True Negative Rate)은 흔히 특이도로 불리는데 음성인 케이스에 대해 음성으로 잘 예측한 비율을 의미합니다.
따라서 FPR은 음성인 케이스에 대해 양성으로 잘못 예측한 비율을 의미합니다.
종합하자면 TPR은 높을수록 좋은 수치입니다. 반대로 FPR은 낮을수록 좋은 수치입니다.

따라서 그래프에서 확인했을 때 선이 좌상단으로 위치할수록 좋은 모델이라고 할 수 있습니다.
그러면 좌상단이라는 것을 수치적으로 확인할 수 있을까요?
바로 그래프 아래 면적을 통해 알 수 있습니다.
좌상단으로 향할수록 아래 면적이 넓어지기 때문입니다.
이를 나타내는 수치가 AUC(Area Under the Curve)입니다.
위의 모델은 다중 분류 모델이기 때문에 ROC 곡선을 나타낼 수 없지만 예시 코드를 통해서 나타내보겠습니다.
from sklearn.metrics import roc_curve
y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv = 3,
method = "decision_function")
fpr, tpr, thresthresholds = roc_curve(y_train_5, y_scores)
plt.plot([0,1], [0,1], "k--", "r+")
plt.plot(fpr, tpr)
plt.xlabel('FPR')
plt.ylabel('TPR')
plt.title('sample ROC curve')
plt.show()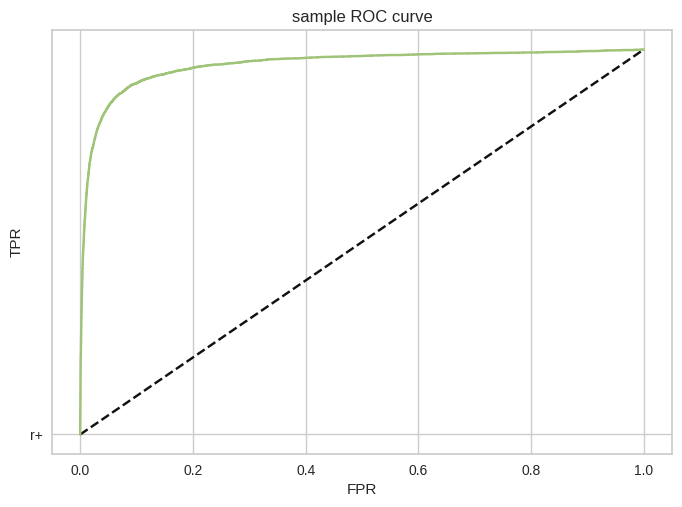
이번 포스팅에서는 머신러닝 분류 문제에서의 전체적인 과정과 결과를 해석하는 방법에 대해 설명드렸습니다.
여기에 여러 모델을 적용시켜서 성능 비교를 해보시면 어떤 모델이 적합한지 알 수 있을 것입니다.
다음 포스팅에서는 경사 하강법과 회귀에 대해 알아보도록 하겠습니다.
포스팅 내용 중 다른 생각이 있는 분 혹은 수정해야 할 부분이 있으시면 댓글을 통해 그 의견을 나눠보면 너무 좋을 것 같습니다.
※ 본 포스팅의 내용은 핸즈온 머신러닝을 참고하였습니다.
'Machine Learning' 카테고리의 다른 글
| [머신러닝#4] 지도학습 - 의사결정 나무(Decision Tree) (0) | 2023.07.06 |
|---|---|
| [머신러닝 기본#2] 경사 하강법 (0) | 2023.06.30 |
| [머신러닝#3] 지도 학습 - 로지스틱 회귀(Logistic Regression) (0) | 2023.06.29 |
| [머신러닝#2] 지도 학습 - KNN (0) | 2023.05.11 |
| [머신러닝#1] 머신러닝 개요 (0) | 2023.05.10 |