저번 포스팅에서 설명드렸던것처럼 머신러닝에는 다양한 알고리즘이 존재합니다.
https://just-data.tistory.com/10
이번 포스팅에서는 그중 KNN에 대해서 알아보겠습니다.
KNN
KNN은 특정 자료의 분류기준을 정할 때, 주변 k개의 데이터가 속하는 클래스들 중에서 가장 많은 클래스로 특정자료를 분류하는 방식을 의미합니다.
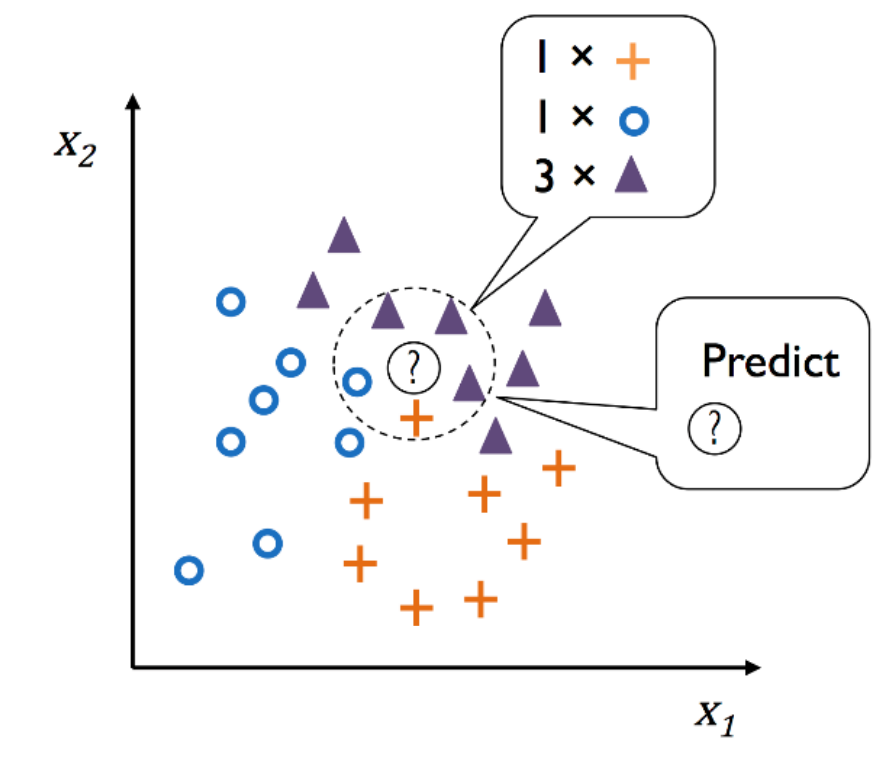
위의 사진처럼 새로운 데이터 ? 가 속하는 클래스를 결정하기 위해 가장 가까운 k개의 데이터(k=5) 클래스들 중 다수투표(major voting) 방식에 의해 최다 출현 클래스로 할당하게 됩니다.
따라서 다음과 같은 특징들이 존재합니다.
- lazy learner
- training data로부터 수학적 모형인 판별 함수를 학습하지 않습니다.
- instance-based learning
- training data 자체가 모형이므로 어떠한 추정 방법도 모형도 없습니다. 즉, 파라미터 추정이 필요 없습니다.
이처럼 KNN은 알고리즘이 매우 간단하지만 성능면에서 뒤처지지 않아 지금까지도 많은 기술에 적용되어 사용되고 있습니다. 또한 학습 데이터 내에 끼어있는 노이즈에 대해 크게 영향을 받지 않습니다.(만약에 엄청 먼 데이터의 경우 반영이 적게 될 것입니다.)
하지만 차원이 증가할수록 데이터의 밀도가 공간의 부피의 증가로 인해 sparse 하다는 단점이 존재합니다.
이를 차원의 저주(curse of dimension)라고 부르고 있습니다.
즉, 데이터의 차원이 증가할수록 성능저하가 심해진다는 것입니다. 다시 말해 KNN은 데이터 수가 많을 때 효과적인 알고리즘이라고 할 수 있습니다.
※ data1은 독립변수가 1개이고 data2는 독립변수가 10개 있는데 관측치는 두 데이터 모두 10개만 존재한다고 가정했을 때의 경우를 상상해 본다면 위의 문제가 왜 발생하는지 이해할 수 있을 겁니다.
더불어 새로운 데이터와 기존 학습 데이터 사이의 거리를 전부 측정해야 하므로, 계산 시간이 오래 걸린다는 한계가 있습니다.
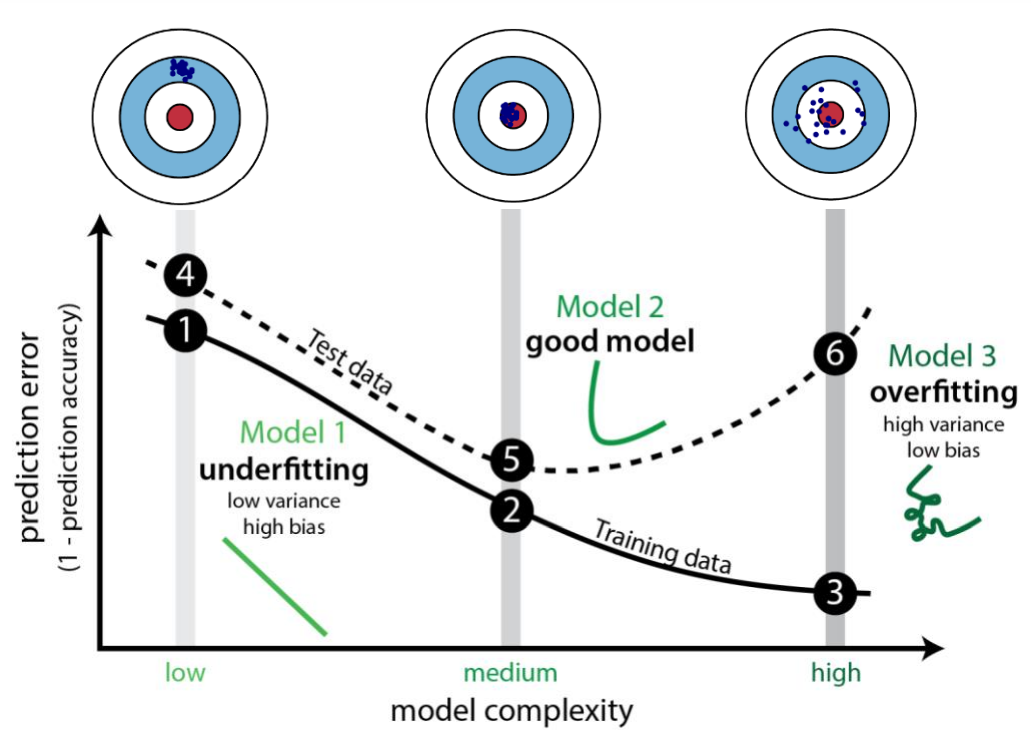
KNN에서는 k의 값을 적절하게 설정하는 것이 매우 중요합니다. 왜냐하면 k에 따라서 모델이 적절하게 적합될지 아니면 과대적합이나 과소적합이 발생할지가 정해지게 되기 때문입니다.
만약, k 값이 작은 경우에는 과대적합(over-fitting)이 발생할 것입니다.
극단적으로 k=1에 대해서 생각해 보면 아래의 사진처럼 근처 1개의 데이터만으로 새로운 데이터를 분류하기 때문에 민감하게 반응하기 때문입니다.

k값이 큰 경우에는 반대로 과소적합(under-fitting)이 발생하게 됩니다.
근처 다수의 데이터로 판단한다면 새로운 데이터의 특성을 제대로 반영할 수 없겠죠?

따라서 validation set을 이용하여 train set와의 성능 비교를 통해 적절한 k값을 산출해야 합니다.
지금까지의 KNN의 장점과 단점에 대해 다시 정리해 보도록 하겠습니다.
- 장점
- 간단한 알고리즘이지만 성능면에서 뒤처지지 않는다.
- 학습 데이터 내의 노이즈에 크게 영향을 받지 않는다.
- 데이터 수가 많다면 꽤 효과적인 알고리즘이다.
- 단점
- 차원의 수가 증가하게 되면 성능이 떨어질 수 있다.(차원의 저주)
- 새로운 데이터에 대한 예측 시, 기존 학습 데이터와의 거리를 전부 측정해야 하므로 계산 시간이 오래 걸릴 수 있다는 한계점이 존재
이제 python으로 knn를 돌려보도록 하겠습니다.
분류
잘 알려져있는 Iris 데이터의 species를 분류하도록 하겠습니다.
import seaborn as sns
iris = sns.load_dataset('iris')
print(iris.head())
target data인 species를 종속변수로 지정해줍니다.
X = iris.drop('species', axis=1)
y = iris['species']species는 3 종류의 문자열로 이루어진 범주형 데이터이기 때문에 이를 수치형으로 변환해줍니다.
from sklearn.preprocessing import LabelEncoder
import numpy as np
classle=LabelEncoder()
y=classle.fit_transform(iris['species'].values)
print('species labels:', np.unique(y))
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y, test_size=0.3, random_state=1, stratify=y)
print('입력변수(학습데이터) : ', X_train.shape)
print('입력변수(테스트데이터) : ', X_test.shape)
print('종속변수(학습데이터) : ', y_train.shape)
print('종속변수(테스트데이터) : ', y_test.shape)
이제 KNN 모델을 적용해보도록 하겠습니다. 분류 KNN은 sklearn.neighbors의 KNeighborsClassifier을 통해 사용할 수 있습니다.
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=5, p=2)
knn.fit(X_train,y_train)
성능을 평가하기 위해 정확도 및 confusion matrix를 생성하도록 하겠습니다.
from sklearn.metrics import accuracy_score #정확도 계산을 위한 모듈 import
print(accuracy_score(y_test,y_test_pred))
from sklearn.metrics import confusion_matrix
conf=confusion_matrix(y_true=y_test,y_pred=y_test_pred)
print(conf)
위의 정확도는 표준화를 거치지 않은 수치입니다. KNN의 모델 활용을 위해서 간단하게 진행한 점 양해 부탁드리겠습니다. 표준화를 진행하게 되면 아마 수치가 달라질 것입니다. 표준화도 적용해보시면 좋을것 같습니다.
추가적인 KNeighborsClassifier의 정보에 대해 알고 싶으시면 아래의 공식사이트를 통해 확인할 수 있습니다.
https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html
회귀
앞서 설명드린 KNN은 분류의 설명이라서 회귀가 된다는 것에 대해 의아해 하실 수 있지만 똑같은 원리로 진행됩니다. 단지 종속변수의 예측치 계산만 다릅니다.
분류에서는 가장 가까운 k개의 데이터 중 다수 투표 방식을 통해 하나의 클래스를 지정했지만, 회귀에서는 평균을 통해 종속변수를 추정하게 됩니다.
이때 평균을 구하는 방식은 크게 두가지가 존재합니다.
- 단순 회귀
- 가까운 이웃들의 평균을 구하는 방식
- 가중 회귀
- 각 이웃이 얼마나 가까이에 있는지에 따라 가중치를 부여하여 평균을 구하는 방식
y_train_pred = knn.predict(X_train) #train data의 y값 예측치
y_test_pred = knn.predict(X_test) #모델을 적용한 test data의 y값 예측치
print('Misclassified training samples: %d' %(y_train!=y_train_pred).sum()) #학습데이터로 오분류 갯수 확인
print('Misclassified test samples: %d' %(y_test!=y_test_pred).sum()) #테스트데이터로 오분류 갯수 확인간단하게 농어의 길이를 이용해서 무게를 예측해보도록 하겠습니다.
import numpy as np
#농어의 길이
perch_length = np.array([8.4, 13.7, 15.0, 16.2, 17.4, 18.0, 18.7, 19.0, 19.6, 20.0,
21.0, 21.0, 21.0, 21.3, 22.0, 22.0, 22.0, 22.0, 22.0, 22.5,
22.5, 22.7, 23.0, 23.5, 24.0, 24.0, 24.6, 25.0, 25.6, 26.5,
27.3, 27.5, 27.5, 27.5, 28.0, 28.7, 30.0, 32.8, 34.5, 35.0,
36.5, 36.0, 37.0, 37.0, 39.0, 39.0, 39.0, 40.0, 40.0, 40.0,
40.0, 42.0, 43.0, 43.0, 43.5, 44.0])
#농어의 무게
perch_weight = np.array([5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0,
110.0, 115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0,
130.0, 150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0,
197.0, 218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0,
514.0, 556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0,
820.0, 850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0, 1000.0, 1000.0])import matplotlib.pyplot as plt
plt.scatter(perch_length, perch_weight, marker='o', s=50, edgecolor="k", linewidth=1)
plt.xlabel("Length")
plt.ylabel("Weight")
plt.show()
먼저 데이터를 train과 test로 분리해 줍니다. sklearn에서 사용할 train set은 2차원 배열이기 때문에 맞게 변환해줍니다.
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(perch_length, perch_weight, random_state = 42)
X_train = X_train.reshape(-1, 1)
X_test = X_test.reshape(-1, 1)
from sklearn.neighbors import KNeighborsRegressor
regressor = KNeighborsRegressor() #Default: n_neighbors=5, weights='uniform'
regressor.fit(X_train, y_train)
y_pred = regressor.predict(X_test)
y_pred
plt.scatter(X_train, y_train, marker='o', s=50, edgecolor="k", linewidth=1)
plt.scatter(X_test, y_pred, marker='o', s=50, edgecolor="k", linewidth=1)
plt.xlabel("Length")
plt.ylabel("Weight")
plt.show()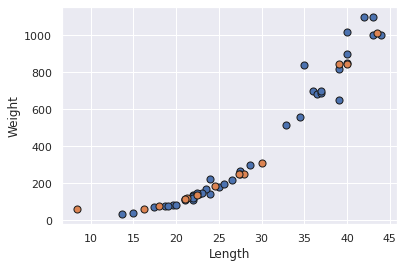
빨간 점이 모델이 추정한 데이터 입니다. 시각적으로 봤을 때, 잘 맞는 것 처럼 보이시나요??
실제로 RMSE를 통해 성능을 평가하고 최적의 k를 구해보도록 하겠습니다.
from sklearn.metrics import mean_squared_error
from math import sqrt
rmse_val = []
for K in range(20):
K = K+1
regressor = KNeighborsRegressor(n_neighbors= K)
regressor.fit(X_train, y_train) #fit the model
pred=regressor.predict(X_test) #make prediction on test set
error = sqrt(mean_squared_error(y_test,pred)) #calculate rmse
rmse_val.append(error) #store rmse values
print('RMSE value for k= ' , K , 'is:', error)
import pandas as pd
curve = pd.DataFrame(rmse_val) #elbow curve
curve.plot()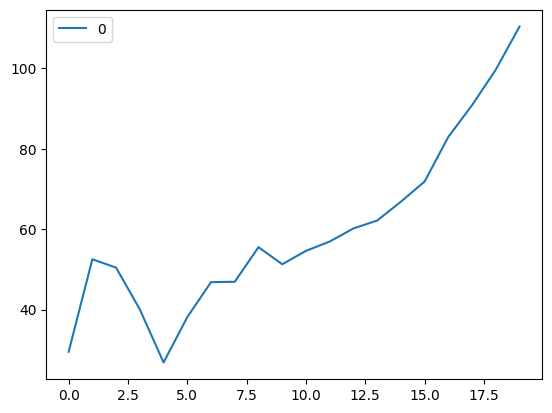
위의 그래프를 보아 k=5에서 가장 잘 나오는 것을 확인할 수 있었습니다.
KNeighborsRegressor에 대해 자세히 알고 싶으시다면 아래의 링크로 들어가면 공식 홈페이지에서 확인할 수 있습니다.
https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsRegressor.html
이번 포스팅에서는 머신러닝 중 지도 학습 모델인 KNN에 대해 살펴보았습니다. 위의 코드 모델을 어떻게 사용하는지에 초점을 맞추었기 때문에 데이터의 전처리, 파라미터 설정, 성능 평가 등에서 부족할 수 있습니다. 앞의 과정에서 추가적으로 필요하신 부분이 있으면 실험의 목적에 맞게 조정하면서 코드를 구성하는 것을 추천 드립니다.
포스팅 내용중 다른 생각이 있는 분 혹은 수정해야할 부분이 있으시면 댓글을 통해 그 의견을 나눠보면 너무 좋을 것 같습니다.
※ 마지막 코드 중 RMSE를 비교하는 코드는 https://riverzayden.tistory.com/11를 참고하였습니다.
'Machine Learning' 카테고리의 다른 글
| [머신러닝#4] 지도학습 - 의사결정 나무(Decision Tree) (0) | 2023.07.06 |
|---|---|
| [머신러닝 기본#2] 경사 하강법 (0) | 2023.06.30 |
| [머신러닝 기본#1] 분류 (0) | 2023.06.29 |
| [머신러닝#3] 지도 학습 - 로지스틱 회귀(Logistic Regression) (0) | 2023.06.29 |
| [머신러닝#1] 머신러닝 개요 (0) | 2023.05.10 |