들어가기 전
본 논문은 e-coomerce 데이터와 같이 대규모 데이터를 이용하여 추천 시스템을 구현할때 유용한 기술을 제안하는 내용입니다. sparse한 전자 상거래 데이터에 적합한 collaborative filtering 접근 방식을 전통적인 데이터 마이닝 추천 시스템과 비교하는 실험 내용을 담고 있습니다.
참고한 자료는 아래와 같습니다.

Introduction
많은 E-commerce 사이트가 생기면서 많은 제품 중에서 선택하는 것은 소비자에게 어려운 문제이다.
이를 위해 등장한 기술중 하나가 협업 필터링(collaborative filtering, CF) 이다.
하지만 CF는 다음과 같은 문제점을 지니고 있다.
- 확장성(scalability)
- 추천의 quality 향상
Contributions
- E-commerce 사이트의 실제 고객 데이터에 대한 추처 시스템의 효과성 분석
- 전통적인 CF, data minig을 포함한 추천 알고리즘의 성능 비교
- 이전 연구보다 온라인 효율성 이점을 가지는 접근 방식(sparse data에서 품질 우위)
Recommender Systems
- Traditional Data Ming: Association Rules
- KDD(Knowledge Discovery in Databses)
- association rules는 일반적으로 support(s)와 confidence(c)로 평가된다.

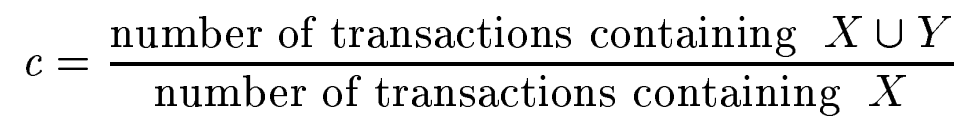
- Collaborative Filtering
- CF는 다른 고객들의 의견을 기반으로 대상 고객에게 제품을 추천한다.
- 논문에서는 해당 모델의 과정을 representation, neighborhood foramtion, recommendation generation의 세가지 하위 작업으로 분할하여 설명하였다.
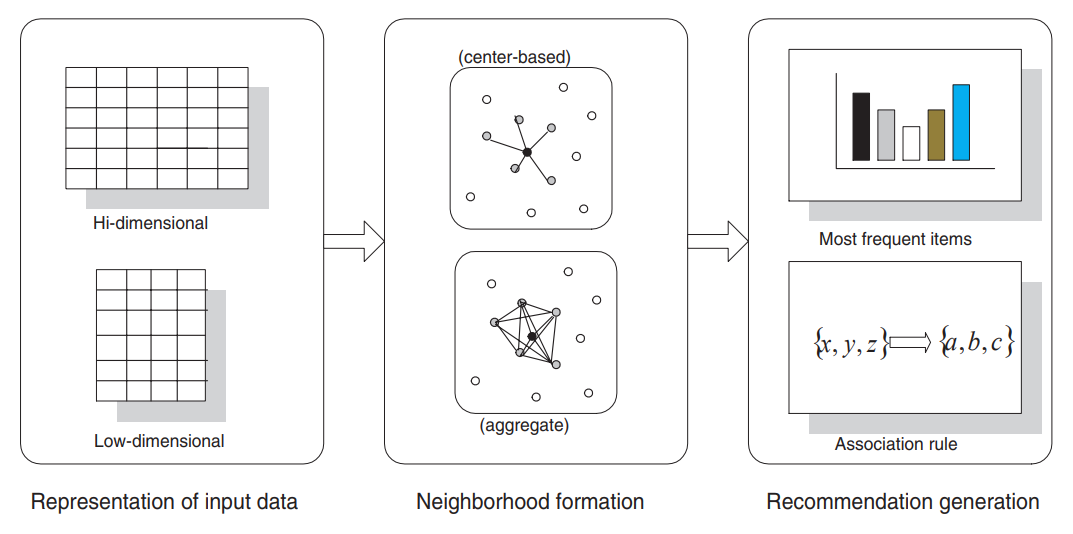
- representaion
- m * n 고객 - 행렬로 나타내면 knn based cf는 다음과 같은 문제 발생 가능
- sparsity
- reduced coverage: 공통된 제품의 구매한 수가 너무 적기 때문에 특정 사용자에 대해 제품 추천이 어렵다
- scalability
- 고객 수와 제품 수 모두에 비례하여 계산이 증가하기 때문에 확장성의 문제 발생 가능
- synonymy
- 서로 다른 제품 이름이 유사한 객체를 가리킬 수 있다.
- 위의 문제를 해결하기 위해 LSI(LSA)를 사용하여 낮은 차원의 표현을 계산 -> SVD(Singular Value Decomposion)를 이용하여 원래 행렬의 순위 k 근사치
- k개의 latent factor를 자기기 때문에 sparsity 문제 완화
- k<n 로 인해 scalability 개선
- latent factor로 인해 동의성 문제 해결
- sparsity
- m * n 고객 - 행렬로 나타내면 knn based cf는 다음과 같은 문제 발생 가능
- neighborhood formation(center-bsed vs aggregate neighborhood)
- peraron 상관계수 또는 cosine 상관계수를 사용하여 고객간의 유사도를 확인후 이웃을 형성한다. 본 논문에서는 두가지 이웃 구성 방법을 비교하여 모델을 선정한다.
- center-based
- aggregate neighbor hood
- peraron 상관계수 또는 cosine 상관계수를 사용하여 고객간의 유사도를 확인후 이웃을 형성한다. 본 논문에서는 두가지 이웃 구성 방법을 비교하여 모델을 선정한다.
- generation of recommendation
- 상위 N개의 추천을 위해 두가지 기술을 비교한다.
- most-frequent item recommendation
- 모든 이웃이 고려되면 빈도수를 기준으로 제품을 정렬하고 아직 구매하지 않은 N개의 frequent한 제품 반환
- association rule-based recommendation
- 위에서 언급한 asscociation rule에 기반하여 제품 반환
지금까지 총 4개의 CF 모델이 소개되었습니다. 소개된 모델들 중 가장 성능이 좋은 모델을 선택하여
전통적인 데이터 마이닝을 이용한 시스템과 비교할 예정입니다.
Data sets
- Moive data
- E-commerce
Experimental Results
- 모든 CF 기반의 실험에서 유사도는 cosine 유사도를 사용하였으며 고객 벡터는 단위 길이로 정규화 되었다.
- 모든 실험에서 추천 수를 상위 10개로 고정
- 이웃 크기 설정
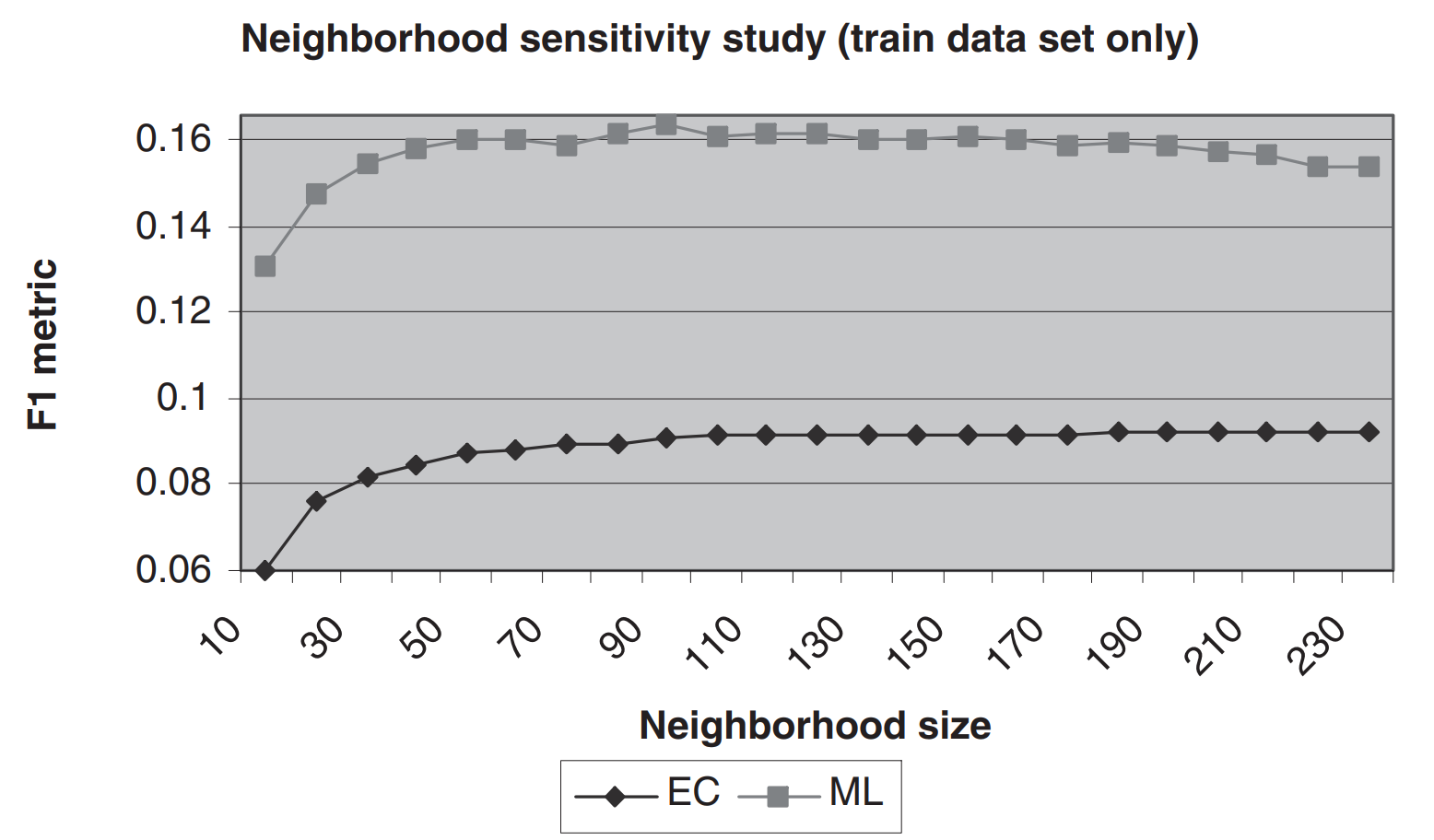
- 이후 실험에서는 ML데이터 셋의 이웃 크기를 90, EC데이터셋의 이웃 크기는 200으로 설정
- 또한 차원 수는 ML데이터 셋의 경우 20, EC 데이터 셋의 경우 300으로 고정하였습니다.
2. 이웃 형성 방법 비교
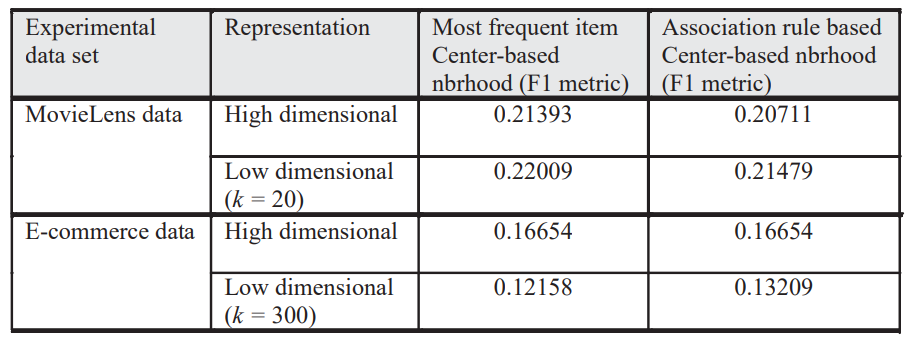
3. recommendation generation 방법 비교
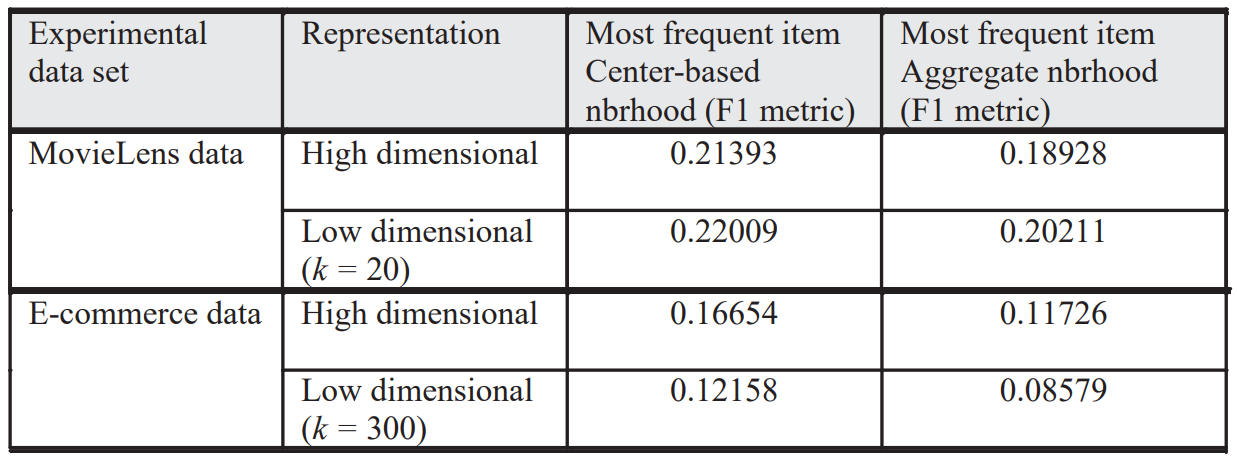
| CF | center-based | aggregate |
| most frequent | 선택된 모델 | |
| association rule |
- 위의 실험으로 CF 기반 다른 알고리즘의 성능을 평가 -> center-based과 most-frequent 방식을 사용하는 CF기반 추천 방식을 전통적인 데이터 마이닝 방식과 데이터 세트의 밀도에 대한 민감도를 평가
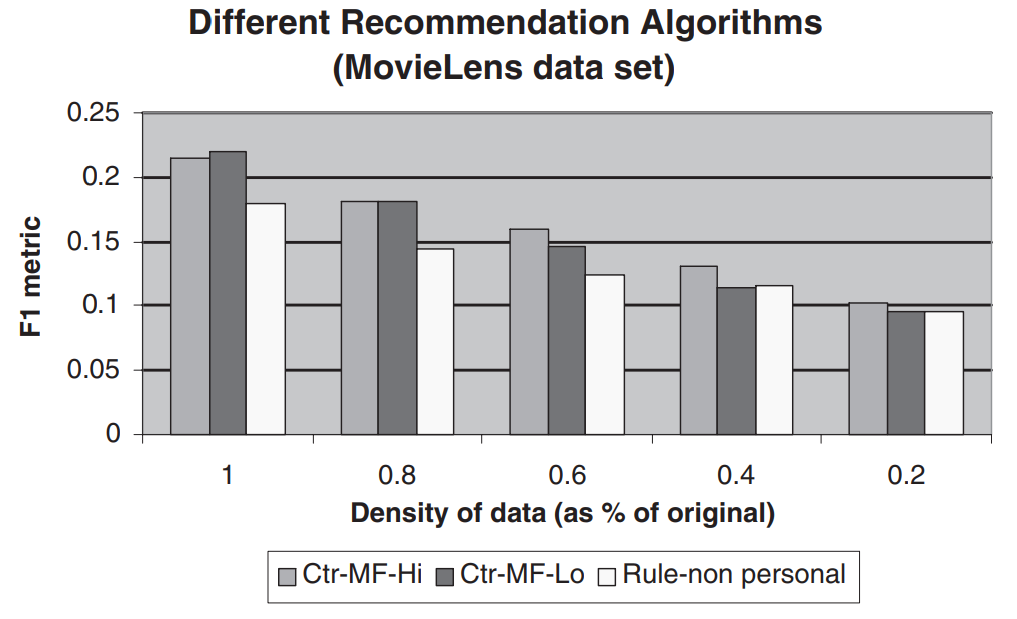
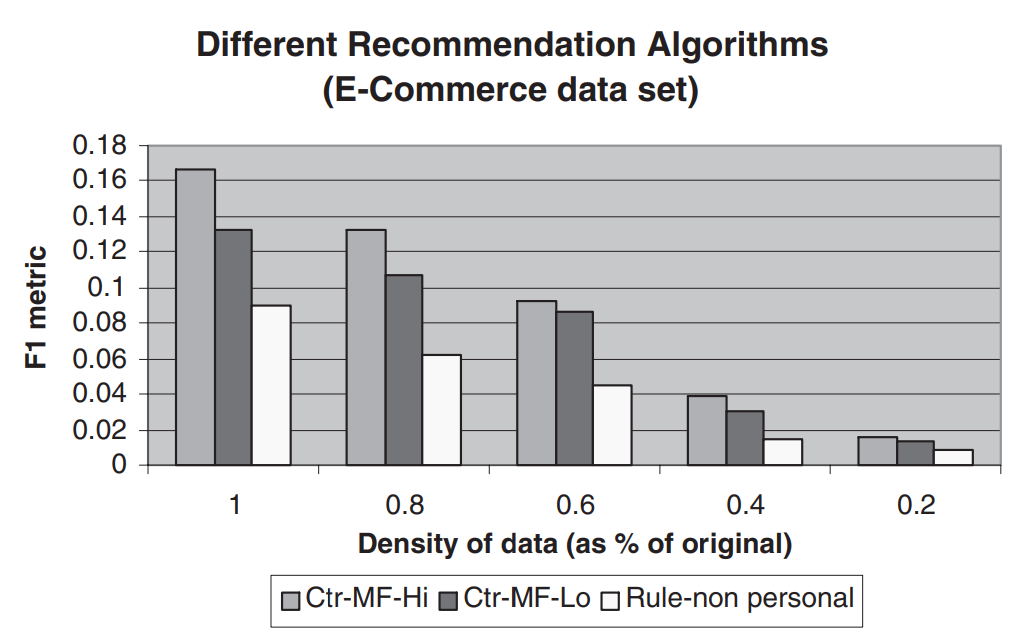
- CF기반 기술이 전통적인 데이터 마이닝 방식보다 성능이 우수
- ML 데이터 셋의 경우 낮은 차원의 모델이 더 나은 성능을 발휘하지만, EC 데이터 셋의 경우 High-dimension 모델이 더 나은 성능을 보인
Conclusion
- 이 논문에서는 CF기반 추천 시스템에 대한 다양한 알고리즘 선택을 평가하였으며, 차원 축소 기술이 대규모 데이터 셋을 확장하는데 도움을 줄 수 있음을 확인
마치며
이번 논문을 리뷰하면서 중간에 제가 생각하기에 약간 이상한 부분(total 데이터를 이용하여 평가 등)은 제외하면서 포스팅을 작성하였습니다. 또한 해당 연구에서는 차원 축소, CF기반 여러가지 알고리즘 등 여러가지 기법들이 등장하였습니다. 따라서 더 깊게 이해하기 위해서는 위의 개념에 대해서 충분히 이해하는것이 필요해 보였습니다. 저는 이번 논문의 핵심은 CF 알고리즘들의 평가, 저차원에서의 모델 성능 평가에 있다고 생각해서 그 위주로 글을 작성해보았습니다. 만약 다른 생각이 있는 분 혹은 수정해야 할 부분들이 있으시면 댓글을 통해 그 의견을 나눠보면 너무 좋을것 같습니다.