들어가기 전
이번에 리뷰할 논문은 추천 시스템을 평가하는 다양한 지표들에 대해서 정리한 논문입니다.
정확도를 제외한 각 지표들은 다양성에 관한 다른 관점들을 가지고 있습니다. 이러한 점에 주목해서 논문을 읽으시면 더욱 도움이 될 것 같습니다. 해당 논문에서 각 지표들간의 관계에 대한 실험 내용이 나와있지만 요약으로 나타내도록 하겠습니다.
참고한 자료는 아래의 링크에서 아래와 같습니다.

Intorduction
기존 추천 시스템 연구는 일반적으로 사용자의 평가를 예측하는 것에 초점을 맞추었다.
하지만 최근 몇 년간 추천 시스템 연구의 중심은 beyond-accuracy의 목표를 포함하도록 변화하고 있다.
검색 결과를 다양화하면 추천 상품 간의 높은 유사성에 관한 문제를 줄일수 있다.
이는 정확성에서 일부 손실을 보더라도 다양성이 사용자 만족도를 높일 수 있다는 점을 시사한다.
Contribution
- beyond-accuracy에 대한 정의 및 최적화 기술에 대한 문헌 검토
- 각 지표간의 관계에 대한 실험 수행
Diversity
Ex. Jaguar에 대해서 검색할 때, 사용자가 원하는 정보가 차일지 동물일지 알 수 없다. 따라서 검색된 문서 목록이 정보 공간의 넓은 영역을 보장하면 사용자의 만족도를 충족시킬 가능성이 높아진다.
- Smyth and McClave [2001] 은 추천 목록의 diversity를 목록 내 항목들 간의 average pairwise distance로 측정하는 것을 제안하였다.
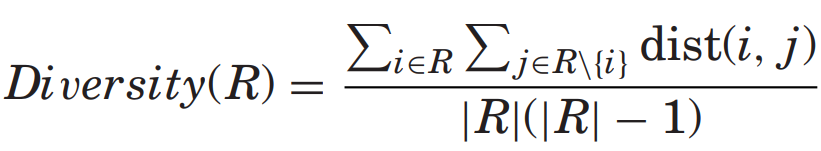
이때 사용되는 항목 거리 함수인 dist는 다양한 방식으로 사용되었다.
- taxonomy based metric
- jaccard similarity
- hamming distance
- pearson correlation
Serendipity
serendipity는 surprise에 크게 의존한다.
Herlocker et al. [2004]은 사용자가 발견할거 같진 않지만 놀랍도록 흥미로운 것이라고 비공식적으로 정의 내렸다.
Murakami et al. [2008]은 생존 추천 시스템의 목표는 예측하기 어려운 항목을 제안하는 것이라고 주장하였다.

Novelty
serendipity와 밀접한 관련이 있다.
IR에서는 사용자가 모른는 관련 문서의 비율로 정의하였다.
Zhang et al. [2002]는 사용자가 이전에 본 문서와의 거리를 기반으로 하는 것으로 정의하였다.
RS(Recommdation System)에서는 일반적으로 사용자가 알지 못하는 항목과 사용자가 이전에 본 항목과 다른 항목에 초점
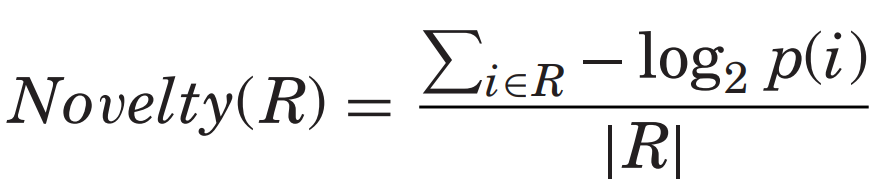
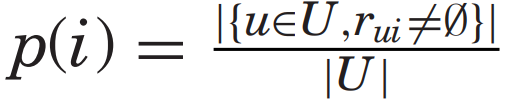
Coverage
- user coverage : 시스템이 사용자를 얼마나 커버하는지
- item coverage : 추천이 가능한 아이템 집합을 얼마나 커버하는지
추천 시스템에서는 후자가 자주 사용되어 이후 정의도 item coverage에 맞춰 설명되어 있다.
: 사용자의 추천 목록에 나타난 항목의 비율
long-tail에 존재하는 아이템의 추천을 늘림으로 인해 사용자의 만족도를 높이고 비즈니스 소유자에게도 이익을 줄수 있다.
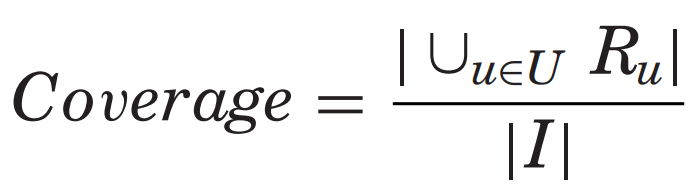
Relationship between indicators
앞에서 정확도 외의 지표들에 대해서 알아보았다면 지금부터는 각 지표들간의 관계에 대해서 연구한 선행 연구들과 통합적으로 알아보기 위한 본 논문의 실험에 대해서 간단히 알아보겠습니다.
Prior research
- Ribero: 다양한 최신 접근 방식들의 accuracy, diversity, novelty 측정
- Bellogin: 평가 기준을 세가지 범주로 분류하여 여러 추천 기법의 성능 평가
- J annach: 추천 알고리즘이 item catalog의 일부에 집중하는 경향을 분석
- Pampin: accuracy, diversity, novelty에서 아이템 기반, 사용자 기반 K-NN방식의 성능을 분석
- Pampin: accuracy, diversity, novelty에서 아이템 기반, 사용자 기반 K-NN방식의 성능을 분석
기존 연구들의 한계
: 지표들간의 관계에 대해서는 깊이 연구되지 않음
Experiment
본 논문에서 진행한 연구의 순서는 아래와 같습니다.
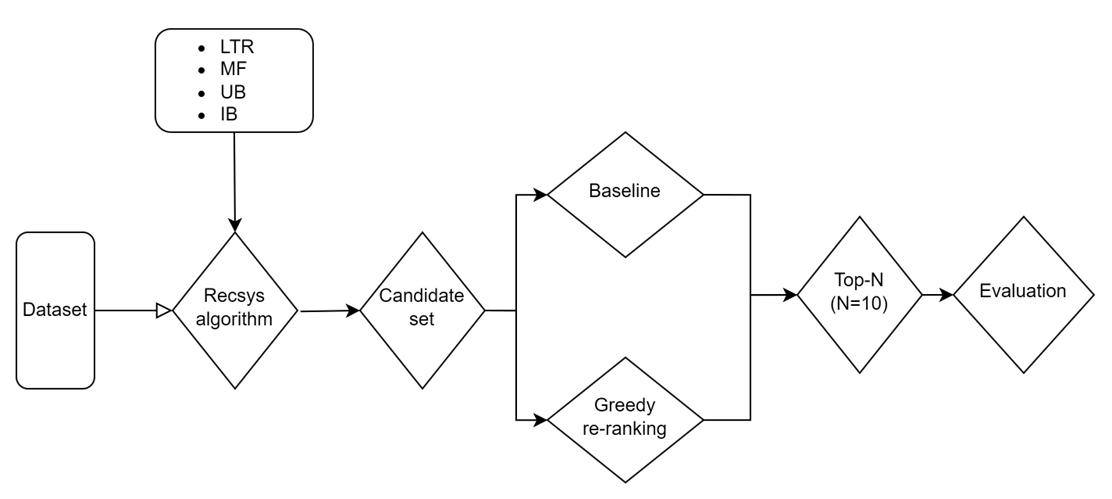
Datasets
- MovieLens
- Last.fm
Recommendation algorithms
- LTR: Pair Learning to rank
- MF
- UB
- IB
Greedy re-ranking
사용자의 만족도를 개선시키기 위해 re-ranking 방식을 사용하였다.
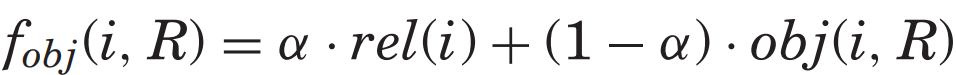
각 지표마다의 다른 obj함수를 사용함으로써 해당 지표들에 대해 최적화 시켜주었다.
Evaluation
One plus random methodology(=negative sampling)
마치며
이번 포스팅에서는 정확도 외의 지표을 설명드리는 것에 초점을 두었기 때문에 실험 과정까지만 언급하고 결과에 대해서는 설명하지 않았습니다. 추천 아이템의 다양성에 대한 논의가 진행되면서 많은 관점들이 등장함에 따라 여러 지표들이 등장했습니다. 그리고 지표들을 정량화하는 과정과 거리 함수의 종류가 다양해졌습니다. 해당 논문은 이러한 선행 연구들의 내용을 담은 review 논문이라고 할 수 있습니다. 각 지표들간 경계와 의미가 헷갈릴수 있고 모호하다고 느껴질수도 있을것 같습니다. 하지만 여러 지표들에 대해 알아놓으면 나중에 시스템에 대해 평가를 할때 목적에 맞게 설계하시는데 도움이 될수 있을거라고 생각합니다. 만약 다른 생각이 있는 분 혹은 수정해야 할 부분들이 있으시면 댓글을 통해 그 의견을 나눠보면 너무 좋을것 같습니다.