들어가기 전
최근 대부분의 추천 시스템은 비슷한 성향을 가진 사용자들 간의 유사도를 이용한 방식을 사용합니다. 이를 협업 필터링(Collaborative Filtering, CF)이라고 하는데요. 이는 크게 메모리 기반 방식(memory-based)와 모델 기반 방식(model-based)으로 나눌 수 있습니다. 이번 포스팅은 모델 기반 CF의 대표적인 예시인 MF(Matrix Factorization)에 대해서 설명하는 논문에 대해서 소개해 드리겠습니다.
참고한 자료는 아래의 링크에서 아래와 같습니다.

Introduction
CF에는 크게 두가지의 영역이 존재한다.
- neighborhood methods
- 아이템 또는 사용자 간의 관계를 계산하는데 중점
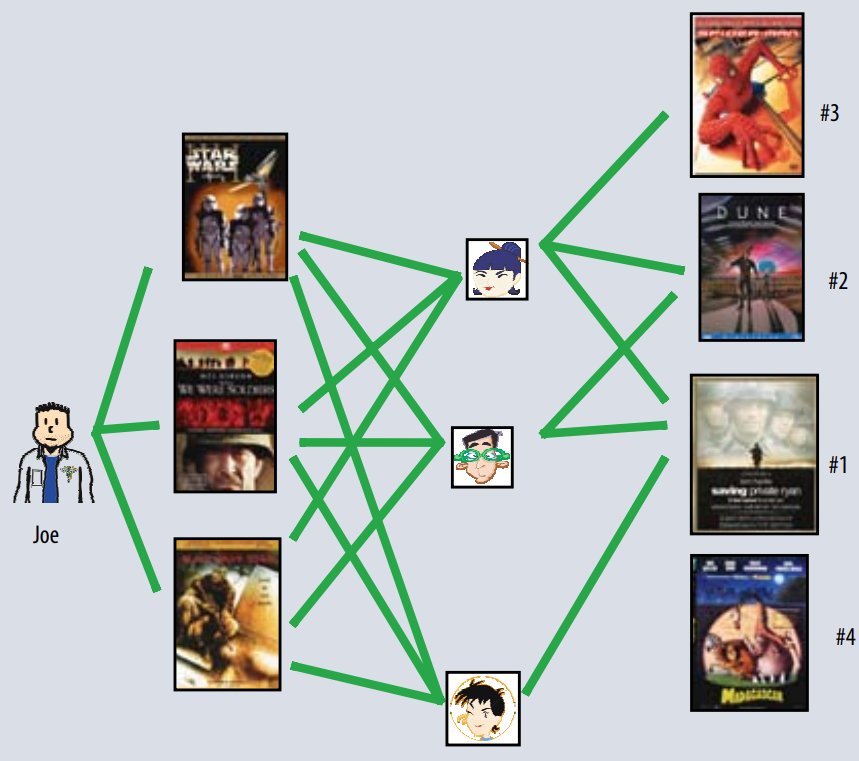
위의 그림처럼 Joe가 봤던 영화를 본 사용자와의 유사도 계산을 통해 다음 영화를 추천하게 된다.
- latent factor models
- 사용자와 아이템에 매겨진 평점 데이터를 이용하여 잠재 요인을 생성하여 이를 이용해 추천하는 방식
- 대표적인 모델로는 MF가 존재
- memory based와의 가장 큰 차이점은 매번 값이 다를수 있다는 점이다.
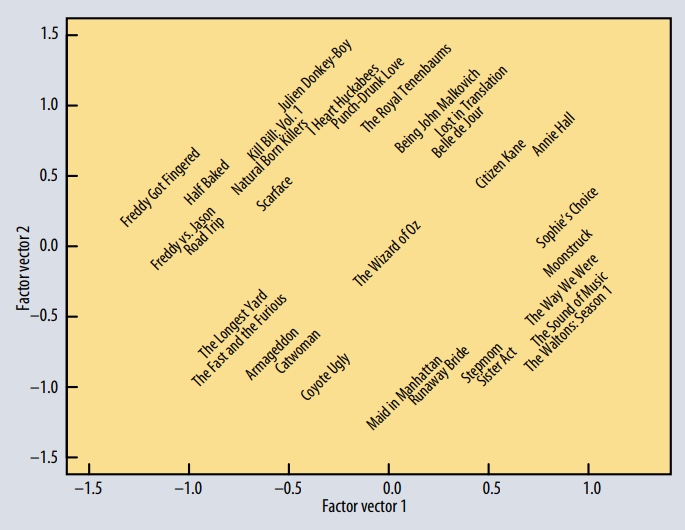
위의 그림은 latent factor = 2로 두었을때의 예시이다.
사용자와 영화를 2개의 latent factor로 나누어 2차원 평면에 투영했을때 사용자와 가장 가까이 위치한 영화를 추천하게 된다.
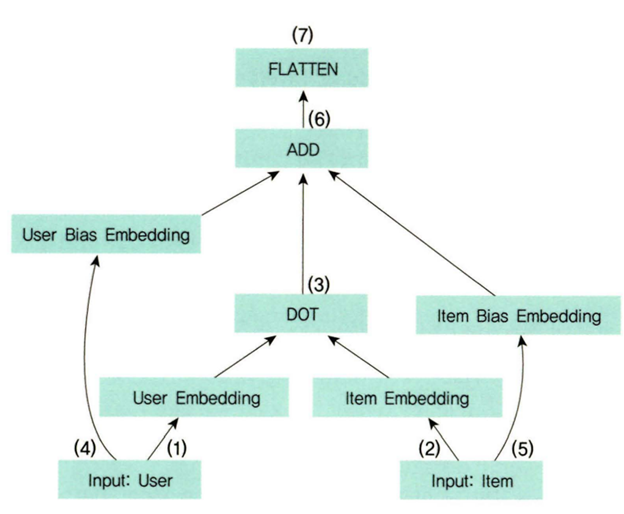
Matrix Factorization
MF의 핵심은 평점 행렬을 사용자 행렬, 아이템 행렬로 분해할수 있다는 점입니다.
그리고 분해된 두 행렬을 내적함으로써 원래의 평점 행렬로 근사시킬수 있습니다.
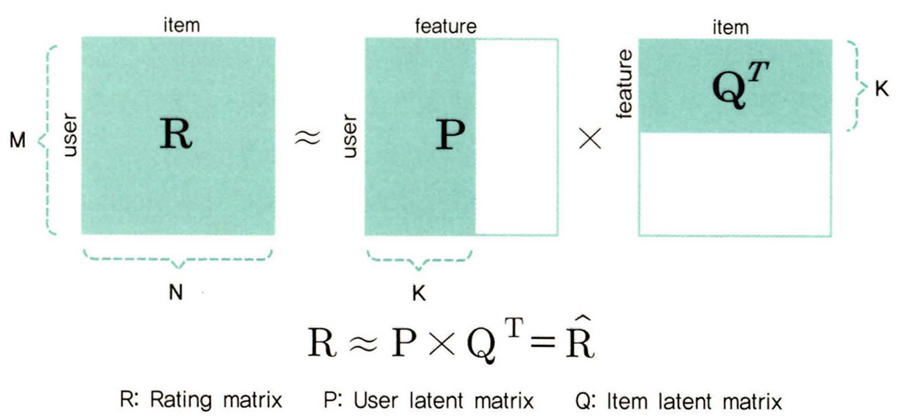
이때, 분해한다는 점에서 SVD(singular Value Decomposition)과 비슷하다고 생각할 수 있지만 SVD는 3개의 행렬로 분해한다는 부분에서 MF와 다른 기법이다. SVD++이라는 모델도 존재하지만 이는 MF에서 조금 더 발전된 방식이다.
Optimize model
사용자와 아이템 행렬을 이용하여 원래의 데이터를 잘 예측하기 위해서 optimize 작업이 필요하다. 이때 실제 평점과 예측 평점과의 차이를 이용해서 학습을 하게 된다.(L2 norm)
본 논문에서는 모델을 학습하기 위해 2가지의 방법을 제시하고 있다.
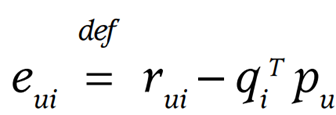
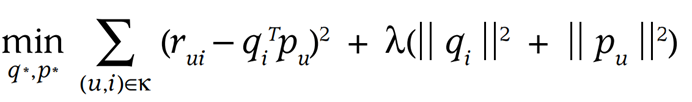
- SGD(Stochastic Gradient Descent)
- 딥러닝 모델에서 자주 사용되는 최적화 방식으로 샘플링된 데이터를 이용해서 가중치를 조절하게 된다.
- convex한 데이터에 효과적이지만 그렇지 않을 경우 local minimum에 빠질 위험성이 존재한다.
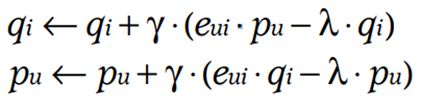
- ALS(Alternating Least Squares)
- 현재 MF는 두개의 행렬을 동시에 최적화하기 때문에 convex하지 않을 가능성이 높다.
- 두 행렬 중 하나를 고정시키고 다른 하나의 행렬을 순차적으로 반복하면서 최적화시키는 방법이다.
- 하나를 고정 시키는 과정에서 non-convex문제가 해결되어 수렴할 수 있다
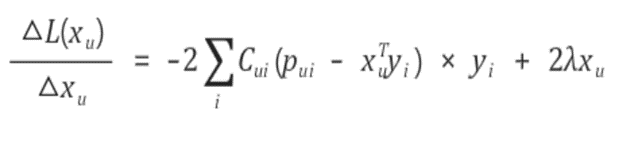
Add Bias
각 사용자와 아이템의 일정한 경향성을 고려해야 한다.
Ex. 어떤 사용자는 보통 2점으로 주는 경향이 있고, 다른 사용자는 일반적으로 4점으로 주는 경향이 있기 때문이다.
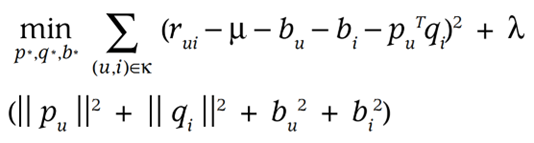
- μ : overall average rating(일반적으로 처음부터 빼주고 모델을 구성한다)
- b_i : observed deviation of item
- b_u : observed deviation of user
Additional input sources
대부분의 평가 데이터는 spase한 특성으로 인해 여러 문제가 발생한다. 따라서 추가적인 정보를 활용하여 이러한 문제를 완화시켜주어야 한다. 대표적인 데이터로는 implicit data를 이용하여 간접적인 정보를 제공하는 것이다.
아래의 N(u)는 implicit feedback에 대한 데이터이다.
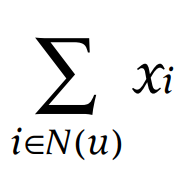

추가적으로 다른 정보(인구 통계학적 정보)도 함께 고려할 수 있다.
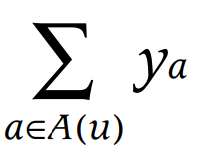
이를 모두 고려한 모델의 예측 평점은 아래와 같다.
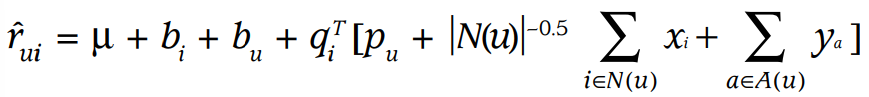
Temporal Dynamics
데이터의 시간적인 동적성을 고려할 수 있다.
왜냐하면 데이터는 시간에 따라서 경향성이 변할 수 있기 때문이다.
이때, 아이템, 사용자, 사용자 요인 편향을 시간적 함수로 고려한다
아이템 요인은 본질적으로 정적이기 때문이다.

Inputs with varying confidence levels
관측된 모든 점수들이 동일한 기준을 따르는 가중치 및 신뢰도를 받는 것은 무리가 있을 수 있다.
이때 신뢰도는 사용자의 행동 빈도에서 비롯될 수 있다.
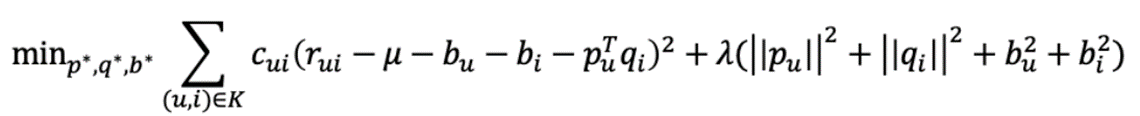
Experiments
아래는 넷플릭스의 데이터를 이용하여 일부 자료를 MF 모델을 통해 2차원 평면(latent factor k = 2)에 투영시킨 그래프이다.
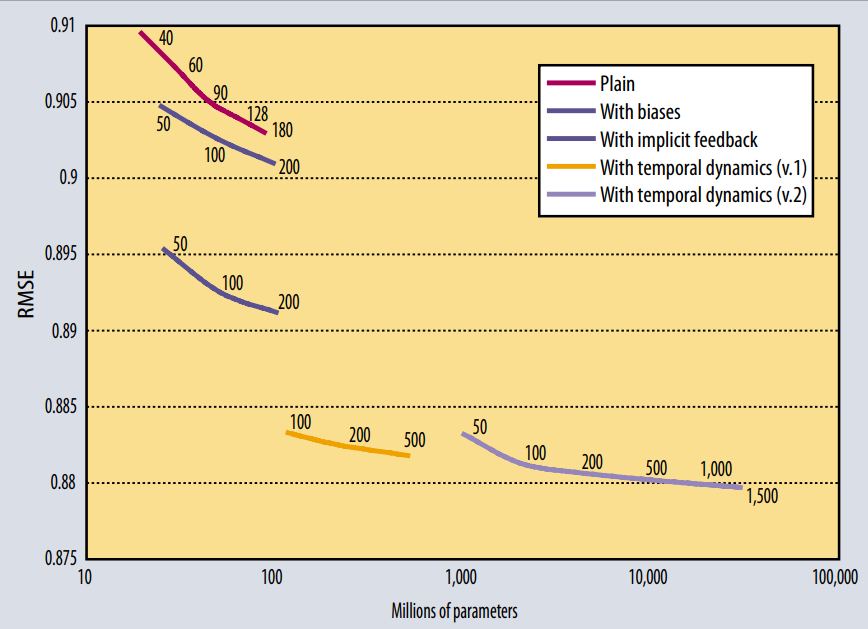
위의 그래프는 MF를 이용한 성능 그래프이다.
다양한 approach 및 매개변수의 변화를 통한 실험한 결과
- 매개 변수의 수를 증가시킴으로써(모델의 복잡성이 증가) 정확도가 향상된다.
- temporal dynamics의 결과를 통해 시간적 영향을 고려하는것이 중요하다.
마치며
MF는 CF방법 중 많이 사용되는 모델 중 하나입니다. 이번 논문은 MF 연구중 가장 대표적인 논문이라고 할 수 있습니다. 행렬 분해를 이용하여 기존의 spase data의 문제를 완화시켰습니다. 더불어 추가적인 implicit data, temporal, confidence level을 고려하는 방법을 제시함으로써 여러가지 데이터에 적용시킬 수 있다라는 것이 큰 시사점인것 같습니다. MF를 간단하게 설명하는 논문이기 때문에 추천 시스템을 공부하시는 많은 분들이 읽어보셨으면 좋겠습니다. 만약 다른 생각이 있는 분 혹은 수정해야할 부분이 있으시면 댓글을 통해 그 의견을 나눠보면 너무 좋을 것 같습니다.