선형 회귀
선형 회귀의 목적은 한 줄로 요약하면 하나 이상의 독립변수($X$)를 사용하여 종속변수($Y$)를 예측하고, 변수 간의 선형적 관계를 정량적으로 설명하는 것이다. 여기서 핵심은 "예측"과 "설명" 두 가지다. 단순히 $Y$의 값을 맞추는 것뿐만 아니라, $X$가 $Y$에 얼마나, 어떤 방향으로 영향을 미치는지를 수치로 표현할 수 있다.
단순 선형 회귀(Simple Linear Regression)
독립변수가 하나인 경우를 단순 선형 회귀라 한다. 모델은 다음과 같다.
$$y = \beta_0 + \beta_1 x + \epsilon$$
- $x$: 독립변수(independent variable): 입력 feature에 해당한다.
- $y$: 종속변수(dependent variable): 예측하려는 target이다.
- $\beta_0$: 절편(intercept): $x = 0$일 때 $y$의 기대값이다.
- $\beta_1$: 기울기(slope): $x$가 한 단위 증가할 때 $y$의 변화량이다.
- $\epsilon$: 오차항(error term): 모델이 설명하지 못하는 나머지 부분이다.
기하학적으로 이 모델은 2차원 평면 위의 직선 하나를 찾는 것이다. 데이터 포인트 $(x_i, y_i)$들이 흩어져 있을 때, 이 점들을 가장 잘 설명하는 직선 $ y = \beta_0 + \beta_1 x$를 구하는 것이 목표다.
다중 선형 회귀(Multiple Linear Regression)
독립변수가 여러 개인 경우를 다중 선형 회귀라 한다. 독립변수가 $p$개이면 모델은 아래와 같다.
$$y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \cdots + \beta_p x_p + \epsilon$$
이를 벡터와 행렬로 표현하면 훨씬 깔끔해진다. $n$개의 데이터에 대해:
$$\mathbf{y} = \mathbf{X}\boldsymbol{\beta} + \boldsymbol{\epsilon}$$
여기서 각 요소는 다음과 같다.
$$\mathbf{y} =
\begin{pmatrix}
y_1 \\
y_2 \\
\vdots \\
y_n
\end{pmatrix}, \quad
\mathbf{X} =
\begin{pmatrix}
1 & x_{11} & x_{12} & \cdots & x_{1p} \\
1 & x_{21} & x_{22} & \cdots & x_{2p} \\
\vdots & \vdots & \vdots & \ddots & \vdots \\
1 & x_{n1} & x_{n2} & \cdots & x_{np}
\end{pmatrix}, \quad
\boldsymbol{\beta} =
\begin{pmatrix}
\beta_0 \\
\beta_1 \\
\vdots \\
\beta_p
\end{pmatrix}, \quad
\boldsymbol{\epsilon} =
\begin{pmatrix}
\epsilon_1 \\
\epsilon_2 \\
\vdots \\
\epsilon_n
\end{pmatrix}$$
$X$는 $n \times (p + 1)$ 행렬로, 첫 번째 열은 절편을 위한 1로 채워진다(이를 디자인 행렬(design matrix)이라 한다). 이전 선형대수 포스팅에서 다뤘던 행렬-벡터 곱 $X \mathbf{\beta}$는 각 데이터 포인트에 대한 예측 $\hat{y}_i = \beta_0 + \beta_1 x_{i1} + \cdots + \beta_p x_{ip}$을 한 번에 계산하는 것이다.
"선형"이 의미하는 것
선형 회귀에서 "선형"은 파라미터 $\beta$에 대해 선형이라는 뜻이지, 반드시 $x$에 대해 선형이라는 뜻이 아니다. 즉 모델의 출력이 파라미터 $\beta$들의 linear combination으로만 이루어져 있느냐를 보는 것이다. 예를 들어 아래 모델도 선형 회귀에 포함된다.
$$y = \beta_0 + \beta_1 x + \beta_2 x^2 + \epsilon$$
$x^2$이 있어서 그래프는 포물선이지만, $x_1 = x, x_2 = x^2$으로 놓으면 파라미터 $\beta_0, \beta_1, \beta_2$에 대해 선형이다. $x$와 $x^2$은 그냥 "이미 정해진 숫자"니까 데이터가 주어진 시점에서 이 모델은 $\beta$에 대한 선형식이 된다. 반면 $y = \beta_0e^{\beta_1x} + \epsilon$같은 모델은 $\beta_1$이 지수 안에 들어가므로 비선형 회귀가 된다.
모델 가정
선형 회귀가 올바르게 작동하려면 몇 가지 가정이 필요하다. 이 가정들이 어떤 상황에서 왜 필요한지를 이해하는 것이 중요하다. 가정이 깨지면 추정된 파라미터의 신뢰성이 떨어지거나, 추론(inference)이 무의미해질 수 있기 때문이다.
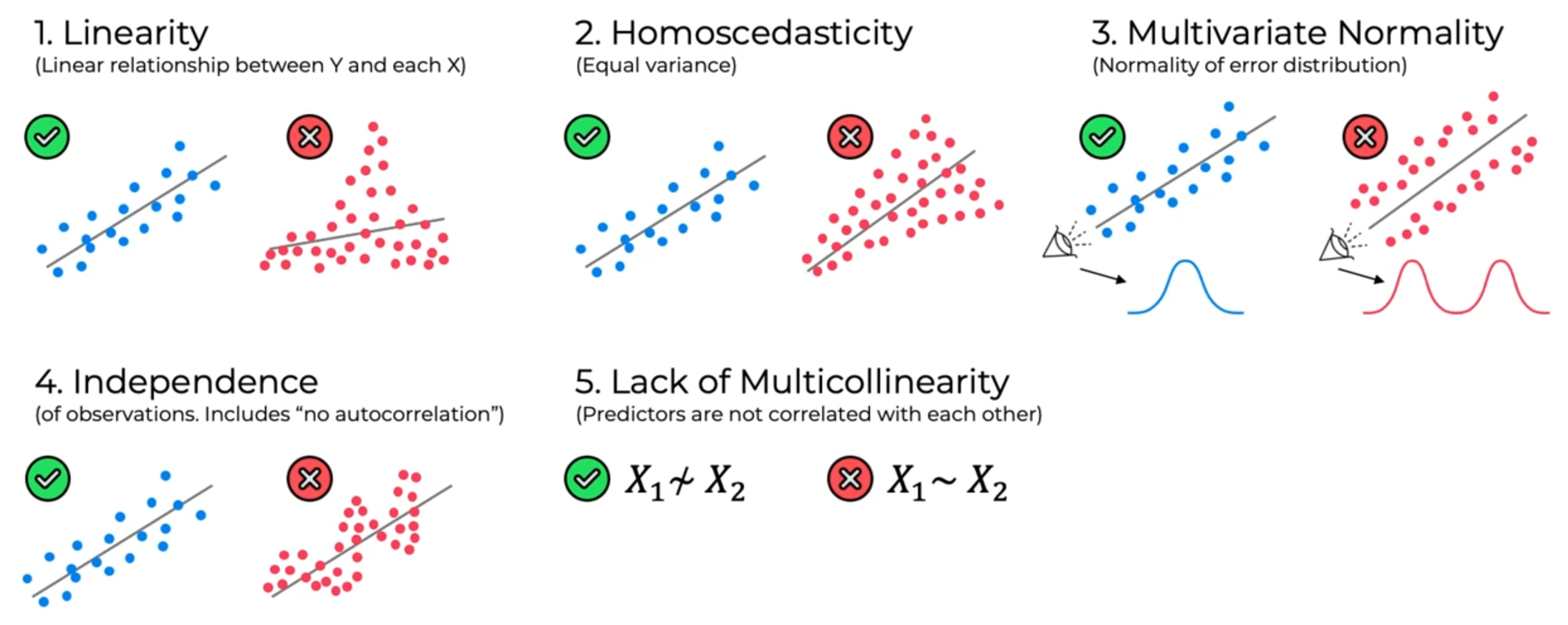
1. 선형성(Linearity)
$$\mathbb{E}[\mathbf{y} \mid \mathbf{X}] = \mathbf{X}\boldsymbol{\beta}$$
종속변수의 기댓값이 독립변수들의 선형 결합으로 표현된다는 가정이다. 앞서 말했등시 이 "선형"은 파라미터에 대한 선형이다. 이 가정이 깨지면 모델 자체가 데이터의 구조를 잘못 표현하고 있는 것이므로, 아무리 좋은 추정 방법을 써도 의미 있는 결과를 얻기 어렵다.
2. 오차의 기대값이 0
$$ \mathbb{E}[\epsilon_i \mid \mathbf{X}] = 0 $$
오차항의 기댓값이 0이라는 가정이다. 직관적으로, 모델이 체계적으로 한쪽으로 편향되어 예측하지 않는다는 뜻이다. 만약 $ \mathbb{E}[\epsilon_i] \neq 0 $이라면 그 편향은 절편 $\beta_0$에 흡수시킬 수 있으므로, 절편을 포함한 모델에서는 자연스럽게 만족되는 가정이기도 하다.
3. 등분산성(Homoscedasticity)
$$\text{Var}(\epsilon_i \mid \mathbf{X}) = \sigma^2, \quad \forall i$$
모든 관측치에서 오차의 분산이 동일하다는 가정이다. 이 가정이 깨진느 상황(이분산성, heteroscedasticity)에서는 OLS 추정량 자체는 여전치 불편이지만 표준오차 추정이 부정확해져서 가설검정이 신뢰할 수 없게 된다.
4. 오차의 독립성(Independence)
$$\text{Cov}(\epsilon_i, \epsilon_j) = 0, \quad i \neq j$$
서로 다른 관측치의 오차가 상관되지 않는다는 가정이다. 시계열 데이터에서는 자기상관(aurocorrelation)으로 인해 이 가정이 깨지기 쉽다.
5. 오차의 정규성(Normality)
$$$$
파라미터 추정 자체보다는 구간추정과 가설검정에 필요한 가정이다. 대표본에서는 중심극한정리에 의해 정규성 가정의 중요성이 줄어든다.
6. 다중공선성의 부재(No Perfect Multicollinearity)
$$\text{rank}(X) = p + 1$$
디자인 행렬 $X$의 열들이 선형 독립이어야 한다. 이전 선형대수 포스팅에서 다뤘던 rank와 직접 연결되는 내용이다. rank가 $p + 1$보다 작으면 $X^TX$가 singular가 되어 파라미터의 유일한 해를 구할 수 없다.
위 가정들을 하나의 수식으로 종합하면:
$$\boldsymbol{\epsilon} \mid \mathbf{X} \sim \mathcal{N}(\mathbf{0}, \sigma^2 \mathbf{I}_n)$$
$ \sigma^2 \mathbf{I}_n $이라는 공분산 구조가 등분산성($\sigma^2이 모두 같음)과 독립성(비대각 원소가 0)을 동시에 표현한다.
파라미터 추정: 최소제곱법(OLS)
모델의 가정을 세웠으니, 이제 파라미터 $\beta$를 어떻게 추정할 것인가의 문제다. 가장 기본적인 방법이 최소제곱법(Ordinary Least Squares, OLS)이다.
목적함수: 잔차제곱합(RSS)
OLS의 아이디어는 단순하다. 예측값 $ \hat{y}_i$와 실제값 $y_i$의 차이(잔차, residual)의 제곱합을 최고화하는 $\beta$를 찾는 것이다.
$$\text{RSS}(\boldsymbol{\beta}) = \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 = (\mathbf{y} - \mathbf{X}\boldsymbol{\beta})^T (\mathbf{y} - \mathbf{X}\boldsymbol{\beta})$$
왜 단순 차이가 아니라 제곱을 사용할까? 이는 양수와 음수 오차가 상쇄되는 것을 방지하고, 큰 오차에 더 큰 패널티를 부여하기 위함이다. 이전 Convex Optimization 포스팅에서 다뤘듯이, RSS는
정규방정식 유도
RSS를 $\beta$에 대해 미분하고 0으로 놓으면 해를 구할 수 있다. 먼저 RSS를 전개하자.
$$\text{RSS} = \mathbf{y}^T \mathbf{y} - 2\boldsymbol{\beta}^T \mathbf{X}^T \mathbf{y} + \boldsymbol{\beta}^T \mathbf{X}^T \mathbf{X} \boldsymbol{\beta}$$
$\beta$에 대해 미분하면:
$$\frac{\partial \text{RSS}}{\partial \boldsymbol{\beta}} = -2\mathbf{X}^T \mathbf{y} + 2\mathbf{X}^T \mathbf{X} \boldsymbol{\beta}$$
이를 0으로 놓으면 정규방정식(normal equation)을 얻는다.
$$\mathbf{X}^T \mathbf{X} \hat{\boldsymbol{\beta}} = \mathbf{X}^T \mathbf{y}$$
가정 6에 의해 $\text{rank}(X) = p + 1$이면 $X^TX$는 nonsingular이므로 역행렬이 존재한다. 양변에 (X^TX)^{-1}$을 곱하면:
$$\hat{\boldsymbol{\beta}} = (\mathbf{X}^T \mathbf{X})^{-1} \mathbf{X}^T \mathbf{y}$$
이것이 OLS 추정량이다. $X^TX$가 singular이면(열들이 linear dependent이면) 해가 유일하지 않고, 이것이 바로 다중공선성 문제다.
Gauss-Markov 정리
가정 1~4, 6이 성립할 때(정규성 가정 불필요), OLS 추정량 $\hat{\beta}$는 BLUE(Best Linear Unbiased Estimator)이다.
- Unbiased: $\mathbb{E}[\hat{\boldsymbol{\beta}}] = \boldsymbol{\beta}$: 추정량의 기댓값이 참값과 일치한다.
- Best: 모든 선형 불편추정량 중에서 분산이 가장 작다.
"Best"라는 것은 같은 조건(선형, 불편)을 만족하는 다른 어떤 추정량보다도 $\hat{\beta}$의 추정 오차가 평균적으로 더 작다는 의미다. 단, 편향을 허용하면(Ridge 등) 분산을 더 줄일 수 있으므로, "모든 추정량 중 최고"라는 뜻은 아니다.
잔차의 성질
OLS 추정 후 잔차 $\mathbf{e} = \mathbf{y} - X\hat{\boldsymbol {\beta}}$는 몇 가지 유용한 성질을 가진다.
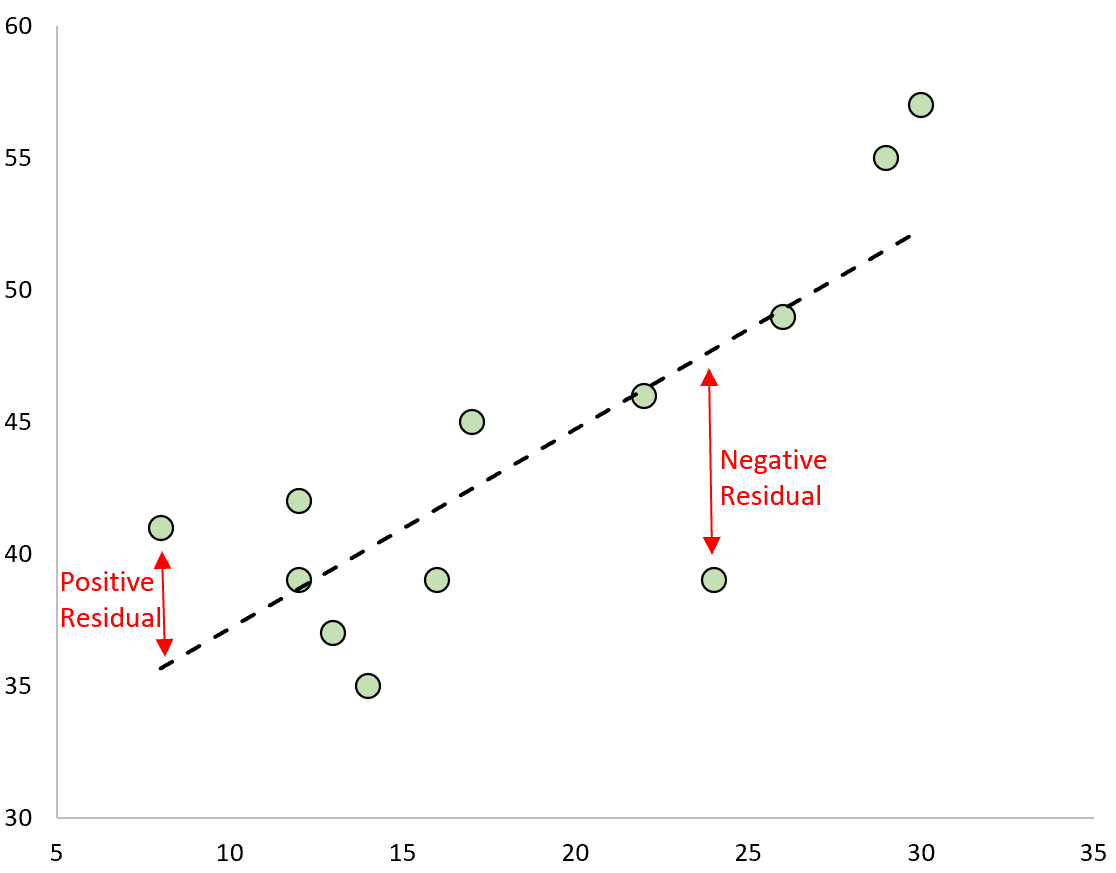
$$X^T\mathbf{e} = 0$$
잔차 벡터가 $X$의 모든 열과 직교한다. 기하학적으로 $\hat{\mathbf{y}} = X\hat{\boldsymbol{\beta}}$는$X$의 열공간(column space)에 대한 $\mathbf{y}$의 정사영(projection)이고, 잔차 $\mathbf{e}$는 열공간에 수직인 성분이다.
또한 $\sum_{i=1}^{n} e_i = 0$이 성립한다($X$의 첫 번째 열이 1이므로). 잔차의 총합이 0이라는 것은 모델이 전체적으로 과대예측이나 과소예측 없이 균형 잡힌 예측을 하고 있다는 뜻이다.
구간추정과 가설검정
OLS로 $\hat{\boldsymbol{\beta}}$를 구했다면, 이 추정값이 얼마나 신뢰할 수 있는지를 정량화해야 한다. 여기서 오차의 정규성 가정(가정 5)이 사용된다.
추정량의 분포
가정 1~6이 모두 성립할 때, OLS 추정량은 다음과 같은 분포를 따른다.
$$\hat{\boldsymbol{\beta}} \sim \mathcal{N}(\boldsymbol{\beta}, \sigma^2(\mathbf{X}^T \mathbf{X})^{-1})$$
개별 계수로 보면:
$$\hat{\beta}_j \sim \mathcal{N}(\beta_j, \sigma^2 [(\mathbf{X}^T \mathbf{X})^{-1}]_{jj})$$
여기서 $ \mathbf{X})^{-1}]_{jj} $는 $( \mathbf{X}^T\mathbf{X} )$의 $j$번째 대각 원소다. 이 값이 클수록 $\hat{\beta}_j$의 불확실성이 크다.
신뢰구간
$\sigma^2$을 모르므로 잔차로부터 추정한다.
$$\hat{\sigma}^2 = \frac{\text{RSS}}{n-p-1} = \frac{\sum_{i=1}^{n} e_i^2}{n-p-1}$$
분모가 $n$이 아니라 $n - p - 1$인 이유는 $p + 1$개의 파라미터를 추정하면서 자유도(degrees of freedom)가 그만큼 줄었기 때문이다. 이를 사용한 $\beta_j$의 $100(1 - \alpha)%$ 신뢰구간은:
$$\hat{\beta}_j \pm t_{\alpha/2, n-p-1} \cdot \text{SE}(\hat{\beta}_j)$$
여기서 $\text{SE}(\hat{\beta}_j) = \hat{\sigma} \sqrt{\left[ (\mathbf{X}^T \mathbf{X})^{-1} \right]_{jj}}$이고 $t_{\alpha/2, n-p-1}$은 자유도 $n - p - 1$인 $t\text{-}$분포의 임계값이다.
가설검정: 개별 계수의 유의성
특정 독립변수 $x_j$가 $y$와 유의한 관계가 있는지 검정하려면
$$H_0 : \beta_j = 0 \quad \text{vs} \quad H_1 : \beta_j \neq 0$$
검정 통계량은:
$$t = \frac{\hat{\beta}_j}{\text{SE}(\hat{\beta}_j)} \sim t_{n-p-1}$$
$|t|$가 크면(p-value)가 작으면 $H_0$을 기각 하고, 해당 변수가 $y$를 설명하는데 유의한 기여를 한다고 판단한다.
모델 평가
변동의 분해
선형 회귀의 성능을 평가하기 위해 $y$의 총변동을 두 부분으로 분해한다.
$$\underbrace{\sum_{i=1}^{n} (y_i - \bar{y})^2}_{\text{SST}} = \underbrace{\sum_{i=1}^{n} (\hat{y}_i - \bar{y})^2}_{\text{SSR}} + \underbrace{\sum_{i=1}^{n} (y_i - \hat{y}_i)^2}_{\text{SSE}}$$
- SST(Total Sum of Squares): $y$의 전체 변동. 모델이 없을 때의 불확실성이다.
- SSR(Regression Sum of Squares): 회귀 모델이 설명하는 변동
- SSE(Error Sum of Squares): 모델이 설명하지 못하는 잔차 변동
직관적으로, SST라는 전체 파이를 "모델이 설명한 부분(SSR)"과 "설명 못한 부분(SSE)"으로 나누는 것이다.

결정계수
$$R^2 = \frac{\text{SSR}}{\text{SST}} = 1 - \frac{\text{SSE}}{\text{SST}}$$
$R^2$은 모델이 $y$의 전체 변동 중 얼마나 설명하는가를 나타내는 비율이다. $0 \le R^2 \le 1$이고, 1에 가까울수록 모델의 설명력이 높다.
그런데 $R^2$에는 한 가지 문제가 있다. 독립변수를 추가하면 $R^2$는 절대 감소하지 않는다. 쓸모없는 변수를 넣어도 $R^2$이 같거나 올라간다. 이 문제를 보정한 것이 수정된 결정계수(Adjusted $R^2$)이다.
$$R^2_{adj} = 1 - \frac{\text{SSE} / (n-p-1)}{\text{SST} / (n-1)}$$
자유도를 반영하여 불필요한 변수 추가에 패널티를 부여한다. 변수를 추가했을 때 SSE의 감소가 자유도 손실을 상쇄할 만큼 충분하지 않으면 $R^2_{adj}$는 오히려 감소한다.
F-검정: 모델 전체의 유의성(ANOVA)
개별 계수의 $t\text{-}$검정은 "이 변수가 유의한가?"를 묻는다. 반면 $F\text{-}$검정은 "모델 전체가 유의한가?$, 즉 모든 독립변수가 동시에 무의미한 것은 아닌지를 검정한다.
$$H_0 : \beta_1 = \beta_2 = \cdots = \beta_p = 0 \quad \text{vs} \quad H_1 : \text{적어도 하나의 } \beta_j \neq 0$$
검정 통계량은:
$$F = \frac{\text{SSR} / p}{\text{SSE} / (n-p-1)} = \frac{\text{MSR}}{\text{MSE}} \sim F_{p, n-p-1}$$
MSR(Mean Square Regression)은 회귀 변동을 자유도로 나눈 것이고, MSE(Mean Square Error)는 잔차 변동을 자유도로 나눈 것이다.$F$값이 크다는 것은 모델이 설명하는 변동이 잔차에 비해 유의미하게 크다는 뜻이다.
이 분해를 정리한 것이 ANOVA(Analysis of Variance) 테이블이다.
| Sorce | SS | df | MS | F |
| Regression | $SSR$ | $p$ | $MSR = \frac{SSR}{p}$ | $\frac{MSR}{MSE}$ |
| Error | $SSE$ | $n - p - 1$ | $MSE = \frac{SSE}{n-p-1}$ | |
| Total | $SST$ | $n - 1$ |
ML 관점에서 선형 회귀의 수학적 구조를 정리하면, 결국 핵심은 세 가지다. 첫째, 모델 설계(가정을 통해 데이터의 구조를 규정), 둘째, 파라미터 추정(OLS로 closed-form solution 도출), 셋째, 모델평가($R^2, F\text{-}$검정으로 설명력 검증). 이 세 단계는 비단 선형 회귀뿐 아니라 거의 모든 ML 모델에 공통되는 프레임워크다. 다만 딥러닝에서는 closed-from solution이 존재하지 않아 gradient descent로 반복 최적화를 하고, $R^2$ 대신 validation loss로 모델을 평가한다는 차이가 있을 뿐, 근본적인 구조는 동일하다.
'Machine Learning' 카테고리의 다른 글
| [머신러닝#4] 지도학습 - 의사결정 나무(Decision Tree) (0) | 2023.07.06 |
|---|---|
| [머신러닝 기본#2] 경사 하강법 (0) | 2023.06.30 |
| [머신러닝 기본#1] 분류 (0) | 2023.06.29 |
| [머신러닝#3] 지도 학습 - 로지스틱 회귀(Logistic Regression) (0) | 2023.06.29 |
| [머신러닝#2] 지도 학습 - KNN (0) | 2023.05.11 |