지난 포스팅에서는 word2vec에 대해서 알아보았습니다.
[NLP#3] 추론 기반(word2vec)
지난 시간에는 통계 기반을 통해 단어의 분산 표현을 얻어내는 방법에 대해서 알아보았습니다. [NLP#2] 통계 기반 저번 포스팅에서는 thesaurus를 통해 컴퓨터에게 자연어의 의미 전달하는 방법에
just-data.tistory.com
이번 시간에는 드디어 RNN에 대해 이야기해보도록 하겠습니다.
잠시 지난 시간의 word2vec을 복습해 보도록 하겠습니다.
word2vec에서는 앞뒤의 맥락을 통해 가운데 target 단어를 예측하는 방식으로 단어 분산 표현을 만들었습니다.


만약 앞뒤가 아니라 왼쪽 맥락만 고려한다면 어떻게 될까요?


사람이 말을 하는 관점으로 보면 두 번째 방식이 오히려 직관적인 것처럼 보입니다. (이와 관련된 언어모델은 이후 포스팅에 등장합니다.)
왜냐하면 얘기를 하는 순서는 $ t-1 $ -> $t+1$ -> $t$이 아니라 $t-2$-> $t-1$ -> $t$이기 때문입니다.
이렇게 바꾸어 단어 분산 표현을 생성하면 더 잘 표현된 단어 분산을 얻을 수도 있을 것입니다.
하지만 word2vec에는 한계점이 존재합니다.
바로 맥락의 개수에 제한이 있다는 점입니다.
※ 맥락의 크기를 길게 해도 한계가 있을 것입니다.
이를 해결하기 위해 등장한 모델이 순환 신경망인 RNN입니다.
RNN은 맥락이 아무리 길더라도 그 맥락의 정보를 기억하는 메커니즘을 갖추고 있습니다.
RNN
RNN(Recurrent Neural Network)에서 Recurrent는 몇 번이나 반복해서 일어나는 일을 뜻합니다.
※이렇게 기억하면 나중에도 모델의 concept를 쉽게 떠올릴 수 있겠죠....?
Recurrent 뜻을 계속 상기하면서 진행하도록 하겠습니다.
아래의 모델 구조를 확인하면 어떻게 순환할 수 있는지를 알 수 있습니다.

설명에 들어가기에 앞서 이르지만 각 계층의 output인 h를은닉 상태(hidden state)라고 부르도록 하겠습니다.
위의 사진에서 알 수 있듯이, 각 시각의 RNN 계층의 input data는 그 계층의 입력 데이터와 바로 전 계층의 hidden state를 받습니다.
※ 초기에는 영행렬의 hidden state를 받습니다.
그리고 이 두 정보를 바탕으로 현 시각의 출력을 계산합니다.
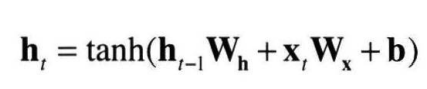

식에서 보시면 이전 출력에 기초해 계산됨을 알 수 있습니다.
그래서 RNN을 상태를 가지는 계층 혹은 메모리가 있는 계층이라고 합니다.
RNN의 한계점
앞서 설명한 RNN은 시계열 데이터의 장기 의존 관계를 학습하기 어렵습니다.
왜냐하면 기울기 소실 또는 폭발이 일어나기 때문입니다.
지금부터는 왜 이런 문제점이 발생하는지 알아보겠습니다.
아래의 그림을 보시면 가중치를 갱신시키는 과정인 backpropagation을 진행할 때 기울기가 tanh와 MatMul(행렬 곱)를 거치는 것을 확인하실 수 있습니다.

RNN의 기울기 소실

tanh 정보를 앞으로 전달하기 위해 미분을 수행하면 $1-y^2$가 됩니다.
이를 그래프로 그려보면 다음과 같습니다.

그래프를 통해 기울기의 값이 0과 1 사이만 가지는 것을 알 수 있습니다.
따라서 backpropagation을 진행할수록 기울기 값이 작아지게 됩니다.
RNN의 기울기 폭발
이번에는 MatMul를 살펴보도록 하겠습니다.
여기서 집중해야될 부분은 앞으로 전달될 때 행렬 곱에서 매번 같은 가중치가 사용된다는 점입니다.
이로 인해 시간이 지날수록 기울기의 크기가 증가하여 기울기 폭발이 발생하게 됩니다.

앞의 두 가지 이유로 인해 전통적인 RNN은 장기 기억을 학습할 수 없게 됩니다.
이를 해결하기 위해 등장한 것이 바로 LSTM입니다.
※ 정확히 얘기하면 gate mechanism이라고 할 수 있겠습니다.
NLP#4까지 공부한 내용의 전개도를 그려보면 다음과 같습니다.

이번 포스팅에서는 RNN에 대해서 간단하게 알아보았습니다.
전체적인 내용을 이해하시면 구체적인 내용을 공부하시는데 큰 도움이 될 것입니다.
다음 글에서는 LSTM에 대해서 이야기 해보도록 하겠습니다.
포스팅 내용 중 다른 생각이 있는 분 혹은 수정해야 할 부분이 있으시면 댓글을 통해 그 의견을 나눠보면 너무 좋을 것 같습니다.
※ 본 포스팅의 내용은 밑바닥부터 시작하는 딥러닝2를 참고하였습니다.
※ 중간 tanh propagation 이미지는 https://techblog-history-younghunjo1.tistory.com/481을 참고하였습니다.
'NLP' 카테고리의 다른 글
| [LLM#1] What? How? 트랜스포머(Transformer) (6) | 2024.11.15 |
|---|---|
| [NLP#5] LSTM (0) | 2023.07.02 |
| [NLP#3] 추론 기반(word2vec) (0) | 2023.05.17 |
| [NLP#2] 통계 기반 (0) | 2023.05.15 |
| [NLP#1] 자연어 처리란? - thesaurus (0) | 2023.05.12 |