만약 기본적인 RNN에 대한 배경지식이 없으시면 간단하게 앞의 포스팅을 보고 오시면 이번 글을 읽으실 때 도움이 되실 겁니다.
[NLP#4] 순환 신경망(RNN)
지난 포스팅에서는 word2vec에 대해서 알아보았습니다. [NLP#3] 추론 기반(word2vec) 지난 시간에는 통계 기반을 통해 단어의 분산 표현을 얻어내는 방법에 대해서 알아보았습니다. [NLP#2] 통계 기반 저
just-data.tistory.com
RNN은 순환 경로를 통해 과거의 정보를 기억할 수 있도록 설계되어 있었습니다
구조도 단순하여 구현도 쉽게 할 수 있습니다.
하지만 기울기 소실, 폭발 등으로 인해 장기 기억을 잘 학습할 수 없어 성능이 좋지 못하다는 큰 단점이 존재합니다.
그래서 장기 기억을 잘 학습할 수 있도록 Gate mechanism이 추가된 LSTM이 등장하였습니다.
이번 포스팅에서는 LSTM의 구조를 알아보고 어떻게 장기 기억이 잘 보존되는지에 대해 알아보겠습니다.
LSTM
먼저 기본 RNN과 LSTM과 비교해 보겠습니다.

비슷하지만 자세히 보면 LSTM은 RNN에 비해 C(기억 cell)를 추가적으로 input 받습니다.
이 부분이 가장 큰 차이점이라고 할 수 있습니다.
그럼 세부적으로 알아보겠습니다.

조금 복잡해 보이지만 LSTM은 크게 Input gate, output gate, forget gate로 이루어져 있습니다.
하나씩 살펴보면 크게 어렵지 않을 겁니다.
그전에 Gate mechanism과 기억 cell에 대해 알아보겠습니다.
Gate mechanism
Gate mechanism의 역할은 다음 단계로 흘려보낼 정보의 양을 제어하는 것입니다.

게이트의 여닫힘 상태는 0.0~1.0 사이의 실수 형태로 나타나는데 여기서 중요한 점은 얼마나 열고 닫을지도 스스로 학습할 수 있다는 점입니다.
0과 1 사이면 어떻게 할지 감이 오시나요?
바로 시그모이드를 통해서 조절하게 됩니다.
또한 정보는 tanh를 통해 전달되게 됩니다.
정리하자면 시그모이드는 gate 역할, tanh는 정보를 비선형으로 변환하는 역할
이 부분을 잘 기억하시고 수식을 보시면 이해가 잘 되실 겁니다.
기억 cell
위에서 언급했던 것처럼 LSTM은 C를 추가적으로 ipnut 받는다는 점에서 기존 RNN이랑 차이점이 있습니다.
이는 기억 셀(memory cell) 또는 셀(cell)이라고 하며, LSTM 전용의 기억 메커니즘입니다.
여기에 과거로부터 시각 t까지에 필요한 모든 정보가 저장돼 있다고 가정합니다.
셀의 특징은 데이터를 출력하지 않고 LSTM 계층 내에서 이동한다는 점입니다.
반면 hidden state는 출력도 되고 다음 계층으로 전달된다는 점에서 셀과 차이점이 있습니다.
이때, hidden state는 셀로부터 계산되는데 식은 다음과 같습니다.
$$h_{t}=tanh(c_{t})$$
이제 LSTM의 구조를 살펴보면서 유기적으로 이해해 보도록 하겠습니다.
Input gate


Input gate는 이전 hidden state($h_{t-1}$)와 현재 input data($X_{t}$)의 정보의 가치가 얼마나 큰지를 판단합니다.
Forget gate
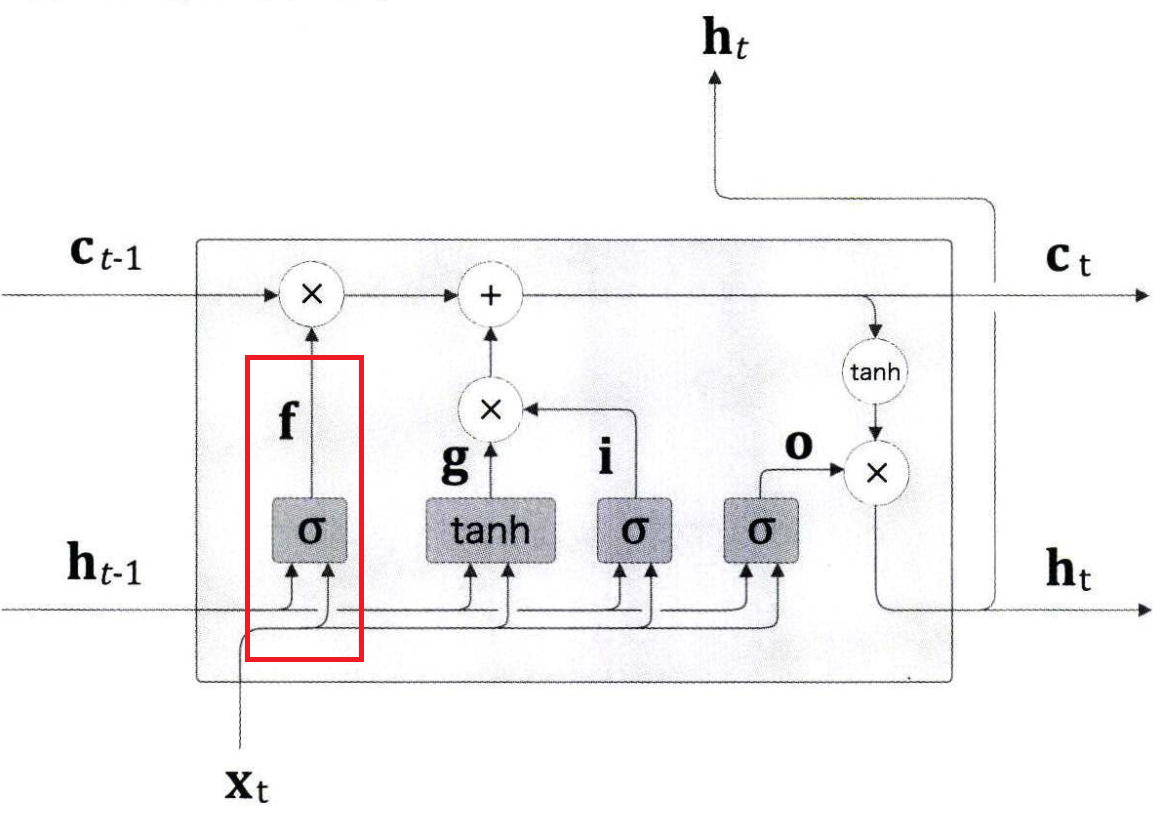

책에서 망각은 더 나은 전진을 낳는다고 표현했습니다.
Forget gate에서는 이전 셀($C_{t-1}$)의 기억의 정보를 얼마큼 버릴지를 판단합니다.
Output gate


Output gate에서는 셀의 정보를 비선형화 한 데이터인 $tanh(c_{t})$가 다음 시각의 hidden state에 얼마나 중요한 가를 판단합니다.
정리
지금까지의 내용을 종합해 보면 LSTM에서의 gate는 모두 이전 시각의 hidden state와 현 시각의 데이터를 사용하여 정보의 중요성을 판단하게 됩니다.
먼저 forget gate를 통해 이전 셀의 정보의 가치를 판단합니다.
두 번째로 input gate에서 현재 데이터에 대한 정보의 중요성을 판단합니다.
그리고 이를 현재 셀에 반영합니다.
※ 저는 이 과정을 셀에 현재 시각을 업데이트한다고 이해했습니다.
마지막으로 현재의 정보가 반영된 셀을 다음 hidden state로 전달하기 전 얼마나 흘려보낼 것인가를 output gate로 판단합니다.
공통적인 부분을 묶어서 과정을 나타내보면 아래와 같습니다.

RNN 한계점 극복
지금까지 LSTM의 구조에 대해 살펴보았습니다.
하지만 이러한 과정이 어떻게 기존 RNN의 한계점을 극복하였는지 잘 와닿지 않을 것입니다.
이번에는 이 원리에 대해 알아보도록 하겠습니다.
그래서 저번 포스팅처럼 LSTM의 기울기의 흐름에 대해 살펴보겠습니다.

그림에서 보이는 것처럼 기울기가 셀에만 집중하여 흘러가게 됩니다.
따라서 지나가는 길에 + 노드와 x노드만 존재하는데요.
첫 번째로 +노드는 이전 기울기를 그대로 전달하기 때문에 기울기의 변화가 일어나지 않게 됩니다.
두 번째로 x노드는 이전의 RNN에서와 달리 원소별 곱 즉, 아다마르 곱을 사용하여 계산하게 됩니다.
즉 매번 새로운 게이트 값을 원소별 곱을 하기 때문에 곱셈의 효과가 누적되지 않아 기울기 소실이 발생하기 어려운 환경이 되는 것입니다.
이것이 Long Short-Term Memory(LSTM)라는 이름이 붙여진 이유라고 생각합니다.
지금까지의 학습 과정을 살펴보면 아래의 전개도와 같습니다.

이번 포스팅에서는 NLP에서 가장 중요하다고 해도 과언이 아닌 LSTM 모델에 대해 알아보았습니다.
실제로 트랜스포머가 나오기 전 LSTM은 여러 분야에서 사용되었습니다.
※ NLP 뿐만 아니라 시계열 모델로써도 사용되었습니다.
또한 gate mechanism을 사용한 모델들도 다수 생겼습니다.
따라서 이 모델의 원리를 이해하는 것은 NLP를 공부하는 과정에서 매우 중요한 부분이라고 할 수 있습니다.
천천히 구성요소를 이해하시면 분명 다른 모델의 이해에도 큰 긍정적인 영향을 끼칠 수 있을 것입니다.
포스팅 내용 중 다른 생각이 있는 분 혹은 수정해야 할 부분이 있으시면 댓글을 통해 그 의견을 나눠보면 너무 좋을 것 같습니다.
※ 본 포스팅의 내용은 밑바닥부터 시작하는 딥러닝 2를 참고하였습니다.
'NLP' 카테고리의 다른 글
| [LLM#2] What? How? BERT (3) | 2024.12.07 |
|---|---|
| [LLM#1] What? How? 트랜스포머(Transformer) (6) | 2024.11.15 |
| [NLP#4] 순환 신경망(RNN) (0) | 2023.06.28 |
| [NLP#3] 추론 기반(word2vec) (0) | 2023.05.17 |
| [NLP#2] 통계 기반 (0) | 2023.05.15 |