최근 ChatGPT, Gemini, LLama 등이 등장하면서 LLM(Large Language Model, 대규모 언어 모델)에 대한 관심이 폭발하고 있습니다.
현재 대부분의 LLM이 트랜스포머(Transformer) 구조를 기반으로 하고 있는 만큼, 트랜스포머에 대해서 이해하지 않고는 LLM과 관련된 기술을 정확히 이해하기 어렵습니다.
따라서, 이번 글에서는 트랜스포머의 구조에 대해서 알아보고 Pytorch로 구현해보도록 하겠습니다.
1. What?
트랜스포머 아키텍쳐는 2017년 구글에서 처음 발표하였습니다.
※ 매우 유명한 논문이니 읽어보는 것을 권장드립니다.
https://arxiv.org/abs/1706.03762
Attention Is All You Need
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new
arxiv.org

본 논문은 첫문단에서 기계 번역에 있어서 RNN(Recurrent Neural Network)의 문제점을 설명하고 있습니다.
- 이전 토큰의 출력을 다시 모델에 입력으로 입력하기 때문에 입력을 병렬적으로 처리하지 못하는 구조
- 입력이 길어지면 먼저 입력한 토큰의 정보가 희석되면서 성능이 떨어진다.
- 층을 깊이 쌓으면 Graeident Vanishing이나 Gradient Exploding 현상이 발생하게 되면서 학습이 불안정해진다.
이를 해결하기 위해 저자들은 Self-Attention이라는 개념을 도입하였습니다.
간단히, 입력된 문장 내의 각 단어가 서로 어떤 관련이 있는지를 학습해서 각 단어의 표현을 조정하는 역할을 합니다.
아래에서 좀 더 자세히 알아보도록 하겠습니다.
그 전에 트랜스포머의 구조는 크게 인코더, 디코더로 이루어져 있으며, 전체적인 구조는 아래의 그림과 같습니다.
※ LLM을 공부하실 분들이면 익숙해져야할 그림이라고 생각합니다.
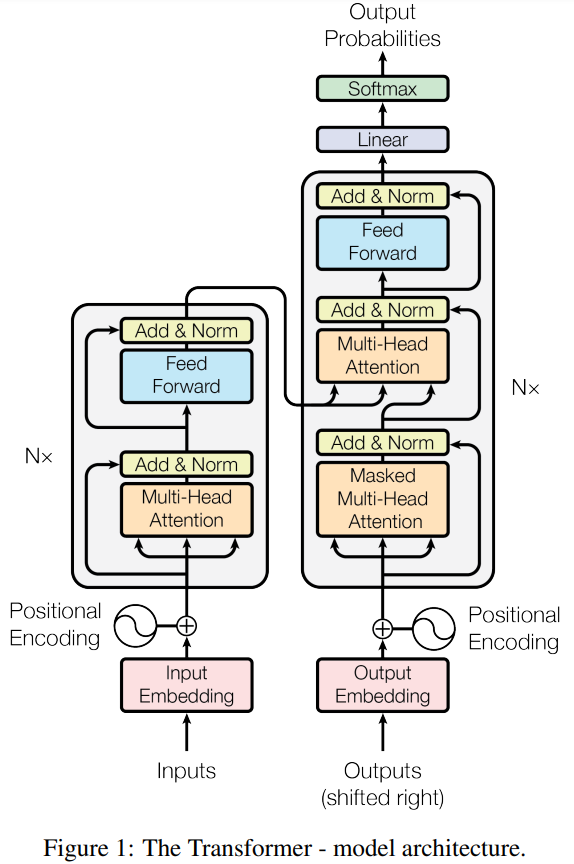
2. How?
트랜스포머의 각 부분들을 살펴보며 코드로 구현해보도록 하겠습니다.
2.1. Encoder
인코더에서는 모델(컴퓨터)가 텍스트를 이해할 수 있도록 numerical한 정보로 변환해주는 역할을 합니다.
이를 위해, 본 연구에서는 Token Embedding과 Positional Embedding을 함께 사용하고 있습니다.
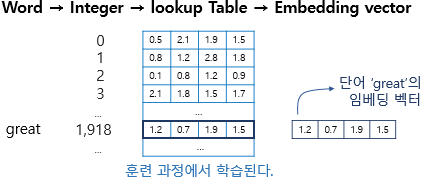
- Token Embedding
텍스트 내 단어들을 정해진 차원의 벡터로 표현합니다.
임베딩에 관한 개념이 익숙치 않으시면 아래 글을 참고하시면 좋을 것 같습니다.
2023.05.17 - [NLP] - [NLP#3] 추론 기반(word2vec)
[NLP#3] 추론 기반(word2vec)
지난 시간에는 통계 기반을 통해 단어의 분산 표현을 얻어내는 방법에 대해서 알아보았습니다. [NLP#2] 통계 기반 저번 포스팅에서는 thesaurus를 통해 컴퓨터에게 자연어의 의미 전달하는 방법에
just-data.tistory.com
import torch
import torch.nn as nn
input_text = "I am studying Transforemr architecture."
input_text_list = input_text.split()
print(f"input_text_list: {input_text_list}")# input_text_list: ['I', 'am', 'studying', 'Transforemr', 'architecture.']
str2idx = {word:idx for idx, word in enumerate(input_text_list)}
idx2str = {idx:word for idx, word in enumerate(input_text_list)}
print(f"str2idx: {str2idx}")# str2idx: {'I': 0, 'am': 1, 'studying': 2, 'Transforemr': 3, 'architecture.': 4}
print(f"idx2str: {idx2str}")# idx2str: {0: 'I', 1: 'am', 2: 'studying', 3: 'Transforemr', 4: 'architecture.'}
input_ids = [str2idx[word] for word in input_text_list]
print(f"input_ids: {input_ids}")# input_ids: [0, 1, 2, 3, 4]
embedding_dim = 8
embed_layer = nn.Embedding(len(str2idx), embedding_dim)
input_embeddings = embed_layer(torch.tensor(input_ids))
input_embeddings = input_embeddings.unsqueeze(0)
input_embeddings.shape# torch.Size([1, 5, 8])- Positional Embedding
RNN과 같이 텍스트 내 순차 정보를 부여합니다.
※ 위치 정보가 없으면, How are you, you are how, are you how를 구별하는 데 제한이 발생할 수 있습니다.

본 연구에서는 Cos, Sin 함수를 사용하였습니다.
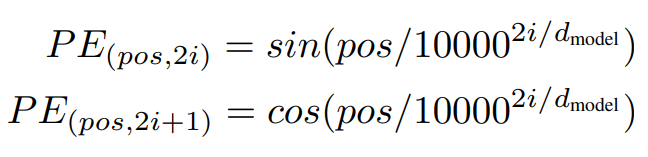
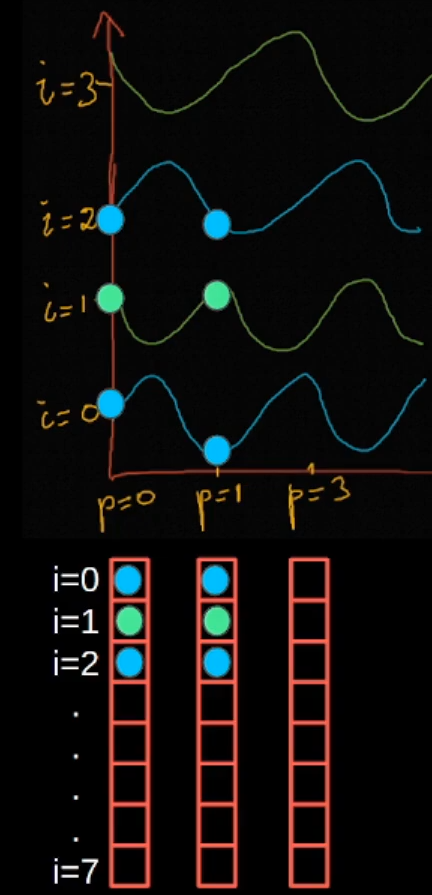
이때, i는 임베딩 벡터 내 인덱스를 의미합니다. 즉, 인덱스가 짝수일 때는 Sin 함수를, 홀수일 때는 Cos 함수를 사용합니다.
import torch
import torch.nn as nn
import math
def get_positional_encoding(seq_len, embedding_dim):
pos_encoding = torch.zeros(seq_len, embedding_dim)
for pos in range(seq_len):
for i in range(0, embedding_dim, 2):
pos_encoding[pos, i] = math.sin(pos / (10000 ** (2 * i / embedding_dim)))
if i + 1 < embedding_dim:
pos_encoding[pos, i + 1] = math.cos(pos / (10000 ** (2 * i / embedding_dim)))
return pos_encoding
seq_len = input_embeddings.size(1)
positional_encoding = get_positional_encoding(seq_len, embedding_dim).unsqueeze(0)
positional_encoding
"""
tensor([[[ 0.0000e+00, 1.0000e+00, 0.0000e+00, 1.0000e+00, 0.0000e+00,
1.0000e+00, 0.0000e+00, 1.0000e+00],
[ 8.4147e-01, 5.4030e-01, 9.9998e-03, 9.9995e-01, 1.0000e-04,
1.0000e+00, 1.0000e-06, 1.0000e+00],
[ 9.0930e-01, -4.1615e-01, 1.9999e-02, 9.9980e-01, 2.0000e-04,
1.0000e+00, 2.0000e-06, 1.0000e+00],
[ 1.4112e-01, -9.8999e-01, 2.9996e-02, 9.9955e-01, 3.0000e-04,
1.0000e+00, 3.0000e-06, 1.0000e+00],
[-7.5680e-01, -6.5364e-01, 3.9989e-02, 9.9920e-01, 4.0000e-04,
1.0000e+00, 4.0000e-06, 1.0000e+00]]])
"""- Final Embedding
최종 임베딩은 Token Embedding과 Positional Embedding을 더한 임베딩을 사용합니다.
input_embeddings += positional_encoding
print(input_embeddings.shape)# torch.Size([1, 5, 8])2.1.1. Attention
논문의 제목 <Attention is All you need>에서도 알 수 있듯이 Attention이라는 개념은 매우 중요합니다.
기본적으로 딥러닝 모델의 구조의 원리는 사람이 생각 혹은 행동하는 방식에서 기인합니다.
이와 마찬가지로 본 연구에서는 사람이 텍스트를 이해할 때 특정 부분에 집중(Attention)한다라는 점에서 비롯됩니다.
예를 들어, 'OO OO OOO 배를 OO'라는 문장이 있을 때, '배'가 신체인지 탈 것인지를 구별할 수 있을 까? 어려울 것입니다.
하지만, '나는 최근 멋있는 배를 탔다'와 같이 앞 뒤 맥락이 주어졌을 때, '탔다'를 통해 탈 것의 '배'라는 것을 알 수 있습니다.
즉, 해당 문장에서 우리는 '배'라는 단어를 이해하기 위해 '탔다'에 집중한 것입니다.
다시 정리하자면, 단어를 구체적으로 표현하기 위해 단어와 단어 사이의 관계를 계산해서 그 값에 따라 맥락을 반영하는 비중을 다르게 설정해야합니다. -> 어텐션 목표
이러한 방식을 어떻게 모델에 녹였는지 알아보도록 하겠습니다.
단어 사이의 관계를 반영하기 위해 연구진들은 쿼리(Query), 키(Key), 값(Value)를 설정하였습니다.
해당 용어들은 정보 검색(Information Retrieval) 분야에서 가져온 용어로써, 우리가 입력하는 검색어를 쿼리, 쿼리와 비교하기 위해 데이터베이스에 존재하는 문서의 특징을 키, 키와 연결된 우리가 원하는 문서를 값이라고 합니다.
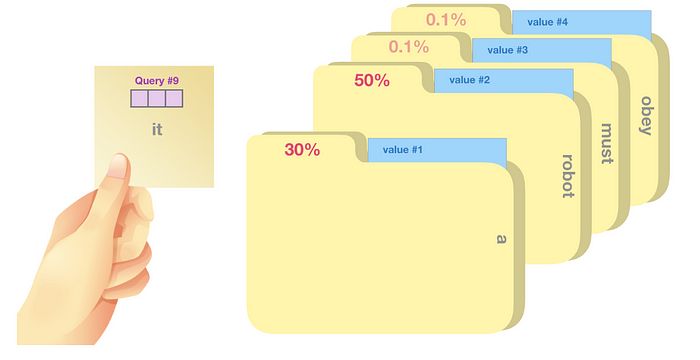
이런 전략을 취하게 되면, 위에서 언급한 어텐션 목표의 1번을 달성하게 됩니다.
이제 2번 '맥락을 반영하는 비율을 다르게 설정'을 생각해 보겠습니다.
만약에, '비율을 모두 고르게 설정'하게 되면 애초에 목표 달성이 힘들게 됩니다. 또한, '거리에 기반해서 설정'하게 되면 그렇지 않을 문장에 대해서 대응이 힘들게 됩니다.
즉, 여기서 알 수 있는 점은 비율은 특정 규칙이 아니라 모델 자체에서 계산되어야 한다는 것입니다.
이해하기 쉽도록 아래 이미지를 통해 살펴보면 이해가 쉬울 것 같습니다.

우선, query, key,value 각각 가중치를 설정합니다.
그리고 특정 단어(토큰)에 대한 쿼리 벡터를 모든 키 벡터들과 곱을 통해 연관성을 계산합니다.
그리고, 해당 값과 값(value) 벡터와의 가중합을 통해 특정 단어에 대한 새로운 결과를 얻을 수 있습니다.
이러한 관점으로 논문에서 제시한 어텐션 그림을 보시면 이해가 잘 될 것입니다.

이를 코드로 구현해보도록 하겠습니다.
from math import sqrt
import torch.nn.functional as F
def compute_attention(querys, keys, values, is_causal = False):
dim_k = querys.size(-1)
scores = querys @ keys.transpose(-2, -1) / sqrt(dim_k)
weights = F.softmax(scores, dim = -1)
return weights @ values
class AttentionalHead(nn.Module):
def __init__(self, toekn_embed_dim, head_dim, is_causal = False):
super().__init__()
self.is_causal = is_causal
self.weight_q = nn.Linear(embedding_dim, head_dim)
self.weight_k = nn.Linear(embedding_dim, head_dim)
self.weight_v = nn.Linear(embedding_dim, head_dim)
def forward(self, querys, keys, values):
outputs = compute_attention(
self.weight_q(querys),
self.weight_k(keys),
self.weight_v(values),
is_causal=self.is_causal
)
return outputs
attention_head = AttentionalHead(embedding_dim, embedding_dim)
after_attention_embeddings = attention_head(input_embeddings, input_embeddings, input_embeddings)
after_attention_embeddings.shape # torch.Size([1, 5, 8])attention을 통과한 임베딩의 사이즈가 기존 사이즈와 동일하다는 것을 알 수 있습니다.
2.1.2. Multi-Head Attention
추가적으로, 트랜스포머 저자들은 하나의 어텐션 연산만 수행하는 것이 아니라 여러 어텐션 연산을 동시에 사용했을 때, 성능이 더 높아진다는 사실을 발견했습니다.
이를 멀티 헤드 어텐션(Multi-Head Attention)이라고 합니다.
수행 방법은 기존 어텐션과 비슷합니다.
1) 헤드(Head)의 수만큼 연산을 수행하기 위해 쿼리, 키, 값을 헤드 수만큼 분할
2) 각각의 어텐션을 계산
3) 입력과 같은 사이즈로 다시 변환
4) 선형층을 통과시켜 최종 결과를 반환
아래는 논문에서 제시한 멀티 해드 어텐션의 그림입니다.
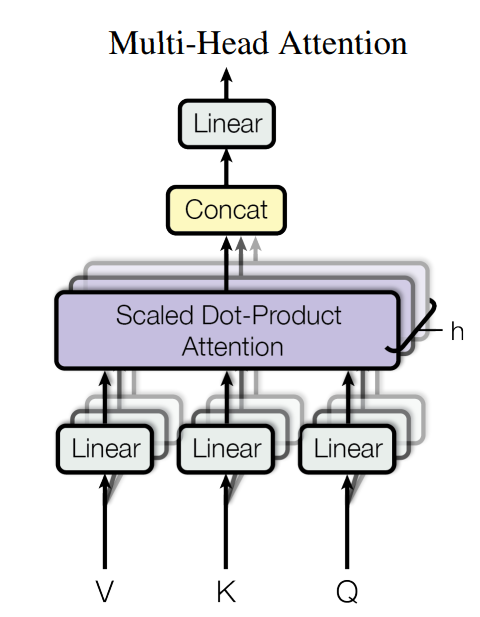
코드로 구현하면 아래와 같습니다.
class MultiheadAttention(nn.Module):
def __init__(self, token_embed_dim, d_model, n_head, is_causal = False):
super().__init__()
self.n_head = n_head
self.is_causal = is_causal
self.weight_q = nn.Linear(embedding_dim, head_dim)
self.weight_k = nn.Linear(embedding_dim, head_dim)
self.weight_v = nn.Linear(embedding_dim, head_dim)
self.concat_linear = nn.Linear(d_model, d_model)
def forward(self, querys, keys, values):
B, T, C = querys.size()
querys = self.weight_q(querys).view(B, T, self.n_head, C // self.n_head).transpose(1, 2)
keys = self.weight_k(keys).view(B, T, self.n_head, C // self.n_head).transpose(1, 2)
values = self.weight_v(values).view(B, T, self.n_head, C // self.n_head).transpose(1, 2)
attention = compute_attention(querys, keys, values, self.is_causal)
output = attention.transpose(1, 2).contiguous().view(B, T, C)
output = self.concat_linear(output)
return output
n_head = 2
mh_attention = MultiheadAttention(embedding_dim, embedding_dim, n_head)
after_attention_embeddings = mh_attention(input_embeddings, input_embeddings, input_embeddings)
after_attention_embeddings.shape #torch.Size([1, 5, 8])
2.1.3. Layer Normalization
딥러닝에서는 입력되는 데이터의 분포를 일정하게 유지시키기 위해 정규화 기법을 사용하고 있습니다.
이때, 정규화 기법은 크게 배치 정규화(Batch Normalization)와 층 정규화(Layer Normalization)으로 나눌 수 있습니다.
※ 이미지 처리에서는 배치 정규화를, 자연어 처리에서는 층 정규화를 주로 사용하고 있습니다.
자연어 처리에서 층 정규화를 주로 사용하는 이유는 입력되는 문장의 길이가 모두 다르기 때문입니다.
만일 자연어 처리에서 배치 정규화를 사용하게 된다면 정규화 대상이 되는 값들 중 대부분이 <PAD> 데이터일 수 있습니다.
이는 사실살 정규화의 효과가 없게 되기 때문에 자연어 처리에서는 각 토큰 임베딩의 평균과 표준편차를 구해 정규화를 수행하게 됩니다.

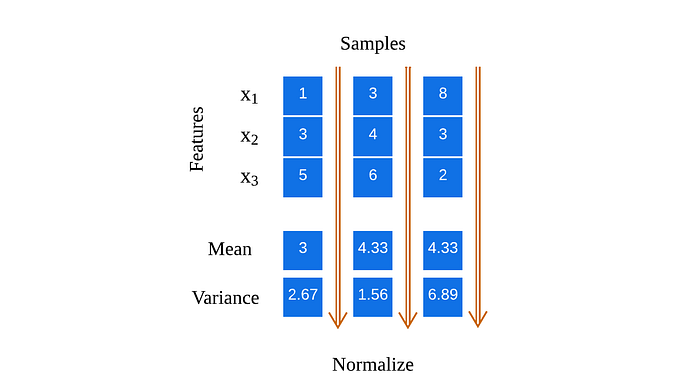
층 정규화는 파이토치에서 제공하는 LayerNorm 클래스를 이용해 간단하게 구현할 수 있습니다.
norm = nn.LayerNorm(embedding_dim)
norm_x = norm(input_embeddings)
norm_x.shape # torch.Size([1, 5, 8])
print(f"평균: {norm_x.mean(dim = -1).data}")# 평균: tensor([[-5.9605e-08, -6.7055e-08, -1.4901e-08, 1.4901e-08, 3.7253e-09]])
print(f"표준편차: {norm_x.std(dim = -1).data}")# 표준편차: tensor([[1.0690, 1.0690, 1.0690, 1.0690, 1.0690]])
2.1.4. Feed Forward Layer
피드 포워드 층(Feed Forward Layer)은 데이터의 특징을 학습하는 완전 연결 층(Fully-Connected Layer)을 의미합니다.
피드 포워드 층은 선형 층, 드롭아웃 충, 층 정규화, 활성 함수로 구성됩니다.
class PreLayerNormFeedForward(nn.Module):
def __init__(self, d_model, dim_feedforward, dropout):
super().__init__()
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.linear1 = nn.Linear(dim_feedforward, d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.activation = nn.GELU()
self.norm = nn.LayerNorm(d_model)
def forward(self, src):
x = self.norm(src)
x = x + self.linear2(self.dropout1(self.activation(self.linear1(x))))
x = self.dropout2(x)
return x2.1.5. Overall structure of Encoder
인코더는 멀티 헤드 어텐션, 층 정규화, 피드 포워드 층이 반복되는 형태입니다.
※ 위 트랜스포머 구조 좌측 인코더 부분에 있는 N이 반복되는 횟수를 나타냅니다.
따라서, 지금까지 배운 각 모듈을 종합해서 인코더를 구축하면 아래와 같습니다.
import copy
class TansformerEncoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward, dropout):
super().__init__()
self.attn = MultiheadAttention(d_model, d_model, n_head)
self.norm1 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(droppout)
self.feed_forward(PreLayerNormFeedForward(d_model, dim_feedforward, dropout))
def forward(self, src):
norm_x = self.norm(src)
attn_output = self.attn(norm_x, norm_x, norm_x)
x = src + self.dropout1(attn_output)
x = self.feed_forward(x)
return x
def get_clones(module, N):
return nn.ModuleList([copy.deepcopy(module) for i in range(N)])
class TransformerEncoder(nn.Module):
def __init__(self, encoder_layer, num_layers):
super().__init__()
self.layers = get_clones(encoder_layer, num_layers)
self.num_layers = num_layers
self.norm = norm
def forward(self, src):
output = src
for mod in self.layers:
output = mod(output)
return output2.2. Decoder
디코더(Decoder)는 생성을 담당하는 부분으로, 앞에서 생성한 토큰을 기반으로 다음 토큰을 생성합니다.
※ 이렇게 순차적으로 생성해야 하는 특징을 인과적(Causal) 또는 자기 회귀적(Auto-Regressive)이라고 부릅니다.
디코더는 인코더와 크게 두 가지 차이점을 가지고 있습니다.
- 디코더에서는 마스크 멀티 해드 어텐션(Masked Multi-Head Attention)을 사용합니다.
왜냐하면 인코더 디코더 모두 완성된 텍스트를 입력으로 받습니다.
하지만, 해당 데이터를 그대로 사용할 경우, 완성될 텍스트를 미리 확인하게 되는 문제가 디코더에서 발생하게 됩니다.
따라서, 이를 막기 위해 아래와 같이 특정 시점에는 그 이전에 생성된 토큰까지만 확인할 수 있도록 마스크를 추가하고 있습니다.

이는 위에서 소개된 어텐션 함수에 조건만 추가해서 구현할 수 있습니다.
from math import sqrt
import torch.nn.functional as F
def compute_attention(querys, keys, values, is_causal = False):
dim_k = querys.size(-1)
scores = querys @ keys.transpose(-2, -1) / sqrt(dim_k)
if is_causal: # Revised Part
query_length = querys.size(2)
key_length = keys.size(2)
temp_mask = torch.ones(
query_length,
key_length,
dtype = torch.bool
).tril(diagnol = 0)
scores = scores.masked_fill(temp_mask == False, float("-inf"))
weights = F.softmax(scores, dim = -1)
return weights @ values
- 디코더에는 크로스 어텐션(Cross Attention)이 있습니다.
디코더에서는 인코더의 결과를 사용하기 위해 크로스 어텐션 연산을 사용하고 있습니다.
※ 아래 그림을 통해 어텐션에 투입되는 데이터가 차이나는 것을 알 수 있습니다.
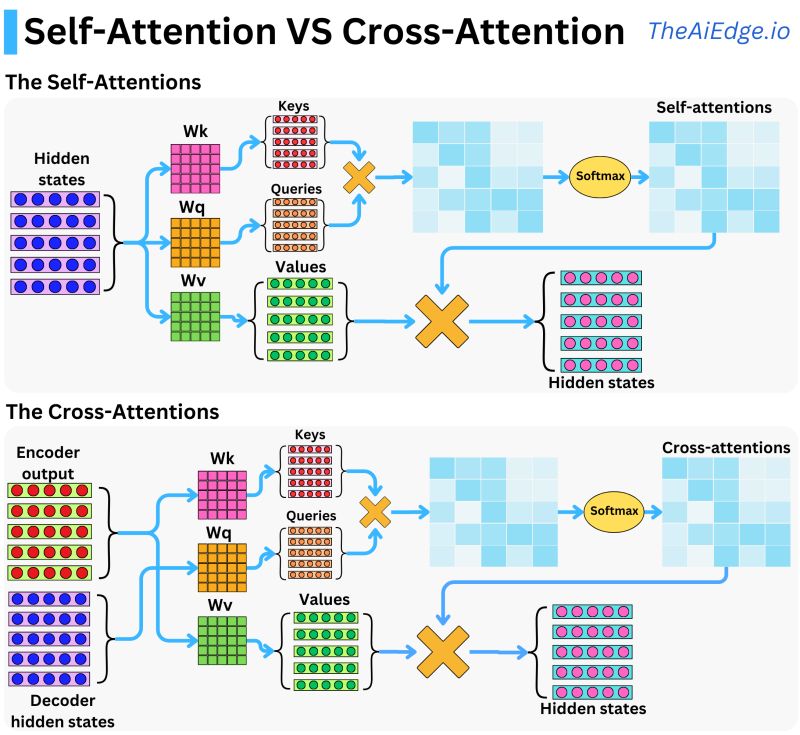
따라서, 최종적으로 디코더 코드는 아래와 같습니다.
class TransformerDecoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1):
super().__init__()
self.self_attn = MultiheadAttention(d_model, d_model, n_head)
self.multihead_attn = MultiheadAttention(d_model, d_model, n_head)
self.feed_forward(PreLayerNormFeedForward(d_model, dim_feedforward, dropout))
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(droppout)
self.dropout2 = nn.Dropout(droppout)
def forward(self, src, tgt, encoder_output, is_causal = True):
# self attention operation
x = self.norm1(tgt)
x = x + self.dropout1(self.self_attn(x, x, x))
# cross attention operation
x = self.norm2(x)
x = x + self.dropout2(self.multihead_attn(x, encoder_output, encoder_output, is_causal = is_causal))
# feed forward operation
x = self.feed_forward(x)
return x
디코더 또한 인코더와 마찬가지로 디코더 층을 여러 번 쌓은 구조로 설계되어 있습니다.
import copy
def get_clones(module, N):
return nn.ModuleList([copy.deepcopy(module) for i in range(N)])
class TransformerDecoder(nn.Module):
def __init__(self, decoder_layer, num_layers):
super().__init__()
self.layers = get_clones(decoder_layer, num_layers)
self.num_layers = num_layers
def forward(self, tgt, src):
output = tgt
for mod in self.layers:
output = mod(tgt, src)
return output
지금까지 트랜스포머의 핵심 부분인 인코더와 디코더를 직접 구현하면서 각 개념을 알아보았습니다.
※ 본 게시물은 <LLM을 활용한 실전 AI 어플리케이션 개발>을 참고하여 작성했습니다.
'NLP' 카테고리의 다른 글
| [LLM#2] What? How? BERT (3) | 2024.12.07 |
|---|---|
| [NLP#5] LSTM (0) | 2023.07.02 |
| [NLP#4] 순환 신경망(RNN) (0) | 2023.06.28 |
| [NLP#3] 추론 기반(word2vec) (0) | 2023.05.17 |
| [NLP#2] 통계 기반 (0) | 2023.05.15 |